Hash Function
A hash function is a crucial component of hashing. It takes an input (often called a key) and returns a fixed-size string of characters, known as a hash code or hash value. The primary purpose of a hash function is to efficiently map data elements to specific locations in a hash table. A good hash function should ideally distribute keys uniformly across the hash table to minimize collisions.
Following are the components of Hashing:
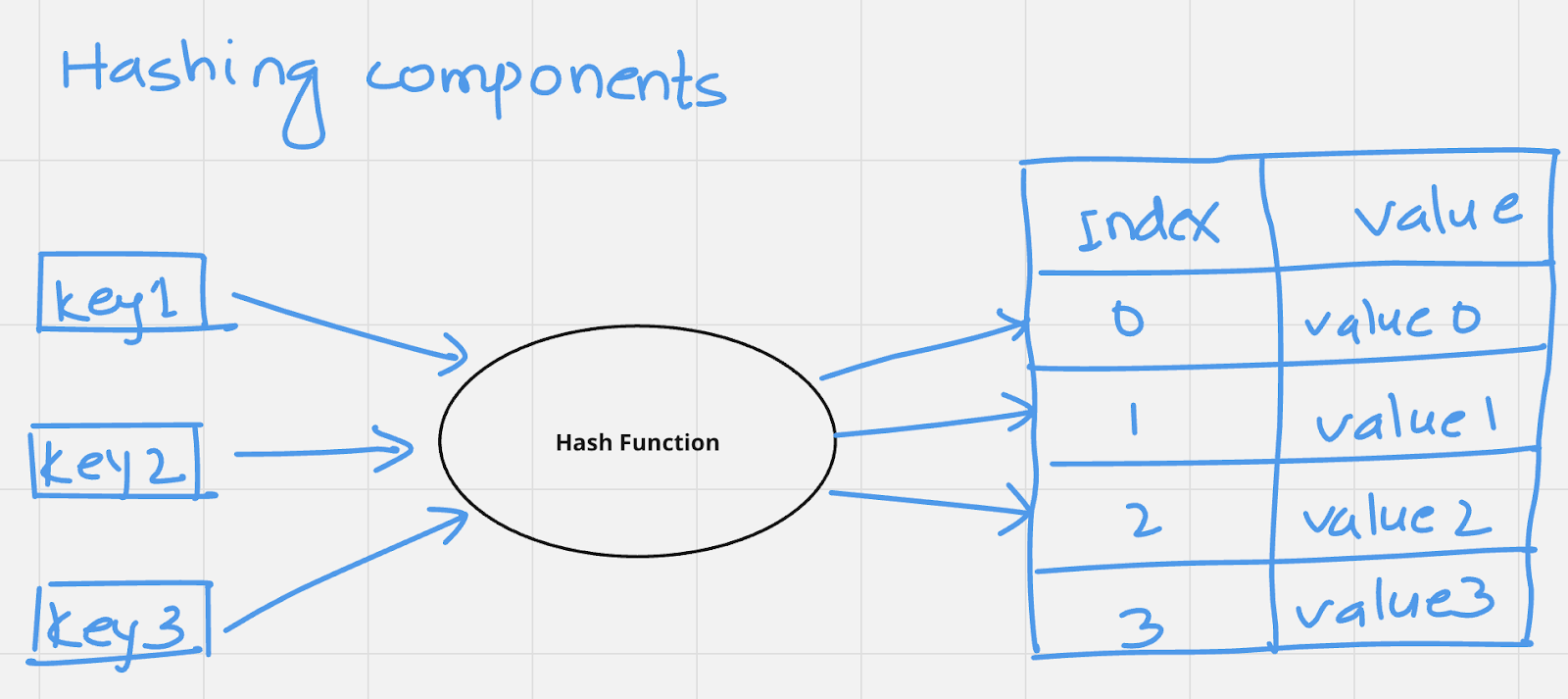
Here are some key characteristics of a good hash function:
Deterministic: For the same input, a hash function should always produce the same hash code.
Uniform Distribution: The hash function should evenly distribute keys across the hash table to reduce the likelihood of collisions.
Efficiency: The hash function should be computationally efficient to calculate.
Minimal Collisions: While collisions are inevitable, a good hash function should aim to minimize collisions as much as possible.
Hash Table:
A hash table is a data structure that uses hashing for efficient storage and retrieval of key-value pairs. It typically consists of an array of fixed size, where each element is called a bucket or slot. Each bucket can store one or more key-value pairs.
Hash table working:
Insertion: When inserting a new key-value pair into the hash table, the hash function is applied to the key to compute its hash code. The hash code determines the index or position in the hash table where the key-value pair will be stored. If there is already a key-value pair stored at that index, a collision occurs, and the collision resolution mechanism (such as chaining or open addressing) is employed.
Retrieval: To retrieve the value associated with a key, the hash function is again applied to the key to compute its hash code. The hash code is then used to locate the corresponding bucket in the hash table, where the value is stored. If collisions occur, the appropriate collision resolution mechanism is used to locate the desired key-value pair.
Hash tables offer constant-time (O(1)) average-case complexity for insertion, retrieval, and deletion operations, making them efficient for a wide range of applications where fast access to data is essential. They are widely used in programming languages, databases, and various software systems for implementing associative arrays, dictionaries, caches, and more.
Example:
Consider an example of hash table of size 20, and the following items are to be stored. Item are in the (key,value) format.
- (1,20)
- (2,70)
- (42,80)
- (4,25)
- (12,44)
- (14,32)
- (17,11)
- (13,78)
- (37,98)
|
Sr.No. |
Key |
Hash |
Array Index |
|
1 |
1 |
1 % 20 = 1 |
1 |
|
2 |
2 |
2 % 20 = 2 |
2 |
|
3 |
42 |
42 % 20 = 2 |
2 |
|
4 |
4 |
4 % 20 = 4 |
4 |
|
5 |
12 |
12 % 20 = 12 |
12 |
|
6 |
14 |
14 % 20 = 14 |
14 |
|
7 |
17 |
17 % 20 = 17 |
17 |
|
8 |
13 |
13 % 20 = 13 |
13 |
|
9 |
37 |
37 % 20 = 17 |
17 |