- Control Of Information System
- Audit Of Information System
- Security Of Information System
- Consumer Layered Security Strategy
- Enterprise Layered Security Strategy
- Extended Validation And Ssl Certificate
- Remote Access Authentication
- Content Control And Policy Based Encryption
- Example Of Security In Ecommerce Transaction
- Enterprise Management Systems (Ems)
- 2.1. Enterprise Software (Erp/Crm/Scm)
- 2.2. Information Management And Technology Of Enterprise Software
- 2.3. Role Of Is And It In Enterprise Management
- 2.4. Enterprise Engineering, Electronic Organism, Loose Integration Vs Full Integration, Process Alignment, Framework To Manage Integrated Change, Future Trends
Data management in the cloud refers to the set of practices, processes, and technologies employed to effectively handle, store, organize, secure, and utilize data within cloud computing environments. Cloud data management encompasses a wide range of activities aimed at optimizing the use of cloud resources while ensuring the integrity, availability, and security of data.
Importance of Data Management in Cloud
- Data Security:
- Cloud data management involves implementing robust security measures to protect sensitive information. This includes encryption, access controls, authentication, and monitoring. Proper data management ensures that confidential data remains secure, even in a shared and distributed cloud environment.
- Data Privacy Compliance:
- Many industries and regions have strict data privacy regulations. Effective data management in the cloud helps organizations adhere to these regulations, such as the General Data Protection Regulation (GDPR) in Europe or the Health Insurance Portability and Accountability Act (HIPAA) in the United States.
- Data Availability and Reliability:
- Cloud data management ensures high availability and reliability of data. Redundancy, backup strategies, and disaster recovery plans are implemented to prevent data loss and ensure business continuity.
- Scalability:
- Cloud environments offer scalability to handle growing amounts of data. Effective data management strategies enable organizations to scale their data storage, processing, and retrieval capabilities as needed, supporting business growth and fluctuating workloads.
- Cost Optimization:
- Proper data management helps optimize costs by efficiently utilizing cloud resources. This includes strategies for data tiering, archiving, and optimizing storage solutions based on access patterns and data lifecycle.
Effectively managing large volumes of data is a significant hurdle when it comes to tasks such as storing data, executing parallel processing, conducting analytical processing, and performing online query execution in the realm of cloud computing. Several analytical data management systems in the cloud include BigTable, HBase, HyperTable, Hive, and HadoopDB. On the other hand, web-based data management systems like PNUTS and Cassandra also play crucial roles in this domain.
b. Google Cloud Bigtable
Developed by Google Inc., Bigtable is a distributed, column-oriented data store designed to efficiently manage vast volumes of structured data linked to the company's Internet search and Web services operations. Serving as a distributed storage system, Bigtable is adept at handling extensive data, reaching the scale of petabytes, utilizing a NoSQL column-oriented data store. This technology is specifically crafted to support Google's internet search and web service functions. Its operation is facilitated by robust database servers, offering advantages such as scalability, straightforward administration, and the ability to maintain cluster elasticity seamlessly, all without experiencing downtime.Bigtable is used to store and query the following types of data:
Time series data
Marketing data
Financial data
Internet of things data
Graph data
The table below illustrates the row and column specifications of the Bigtable storage model. In this model, each column functions as a container for arbitrary values presented as name-value pairs, organized within column families. The number of column families is predetermined at the creation of the table, and these families can store various data values. It's noteworthy that the labels of column families can be established at any given point in time, providing flexibility in the management of the data structure.
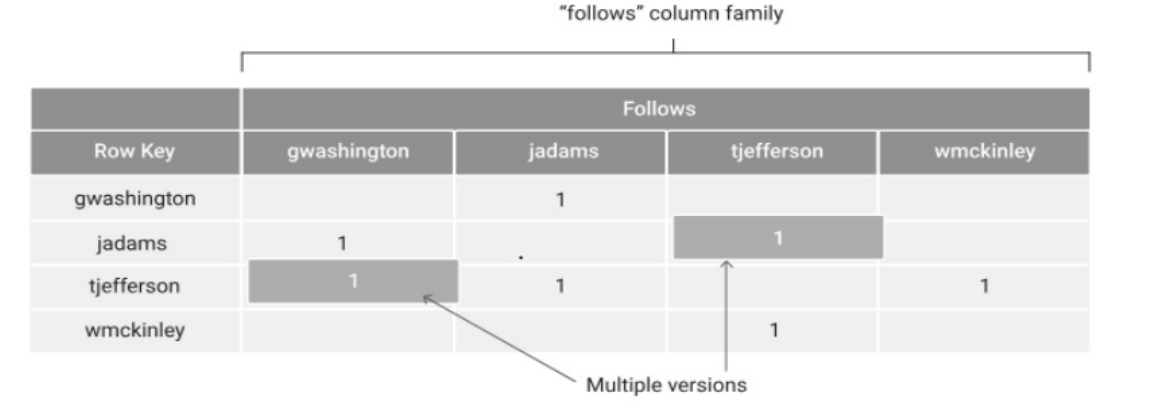
In Bigtable, individual tables are partitioned into distinct row ranges referred to as tablets, each overseen by a dedicated server known as a tablet server. The tablet server manages the storage of each column family within an assigned row range, distributing the data across a distributed file system.
For organizational purposes, Bigtable maintains its meta-data table in a centralized meta-data server. This meta-data table serves the crucial role of locating user tablets in response to read and write operations. To efficiently handle substantial amounts of data, the meta-data table itself is subdivided into multiple tablets. The Root Table plays a key role in pointing to other meta-data tablets, facilitating large-scale parallel reads and simultaneous insert operations on the same table. This design enhances the effectiveness of managing extensive data sets within Bigtable.
b. Google Cloud Datastore
Google Cloud Datastore is a NoSQL document database designed for exceptional scalability, high performance, and robust support for application development.
One of the standout features of Cloud Datastore is its ability to deliver high performance even during periods of high incoming data traffic. It is equipped with ACID properties, ensuring data integrity, and offers high availability to its subscribers.
Cloud Datastore finds applications in scenarios such as:
- Product catalog management, ensuring real-time inventory updates.
- User profiles, providing retailers insights into user preferences based on past interactions.
- Bank transactions, where the ACID property guarantees secure fund transfers.
In the datastore, all data is stored in a single bigtable known as the entity table. This bigtable horizontally distributes data across its disks, referred to as shared storage, and key values are sorted lexicographically. The datastore's architecture enables it to handle concurrent multiple queries from various users by utilizing multiple index tables.