- 1.1 Introduction To Distributed Systems
- 1.2 Examples Of Distributed Systems
- 1.3 Main Characteristics
- 1.4 Advantages And Disadvantages Of Distributed System
- 1.5 Design Goals
- 1.6 Main Problems
- 1.7 Models Of Distributed System
- 1.8 Resource Sharing And The Web Challenges
- 1.9 Types Of Distributed System: Grid, Cluster, Cloud
- Chapter 1 - Slides
- Case Study: Www As Distributed System
- 2.1 Introduction
- 2.2 Communication Between Distributed Objects
- 2.3 Remote Procedure Call
- 2.4 Events And Notifications
- 2.5 Java Rmi Case Study
- 2.6 Introduction To Dfs
- 2.7 File Service Architecture
- 2.8 Sun Network File System
- 2.9 Introduction To Name Services
- 2.10 Name Services And Dns
- 2.11 Directory And Discovery Services
- 2.12 Comparison Of Different Distributed File Systems
- Chapter 2- Slides
- 8.1 Transactions
- 8.2 Nested Transaction
- 8.3 Locks
- 8.4 Optimistic Concurrency Control
- 8.5 Timestamp Ordering
- 8.6 Comparison Of Methods For Concurrency Control
- 8.7 Introduction To Distributed Transactions
- 8.8 Flat And Nested Distributed Transactions
- 8.9 Atomic Commit Protocols
- 8.10 Concurrency Control In Distributed Transactions
- 8.11 Distributed Deadlocks
- 8.12 Transaction Recovery
- 2079 Bhadra-Regular
- 2076 Chaitra, Ashwin- Ioe Old Question Solution, Distributed System
- 2078 Bhadra- Ioe Old Question Solution, Distributed System
- 2069-Chaitra- Ioe Old Question Solution, Distributed System
- 2075- Regular And Back- Ioe Old Question Solution, Distributed System
- 2070-Back- Ioe Old Question Solution, Distributed System
- 2074 Regular/ Back- Ioe Old Question Solution, Distributed System
- 2072 Chaitra / Kartik- Ioe Old Question Solution, Distributed System
- 2079 Bhadra/ 2080 Baishakh- Ioe Old Question Solution, Distributed System
- 2071- Shrawan- Ioe Old Question Solution, Distributed System
- 2071 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Ashadh-Ioe Old Question Solution, Distributed System
PROCESS RESSILIENCE
Process resilience in distributed systems refers to the ability of the system to continue operating correctly despite failures in individual processes or components. This concept is vital for ensuring that distributed systems can handle faults gracefully and maintain service availability and consistency.
Processes can be made fault tolerant by arranging to have a group of processes.A message sent to the group is delivered to all of the “copies” of the process (the group members), and then only one of them performs the required service.If one of the processes fail, it is assumed that one of the others will still be able to function (and service any pending request or operation.
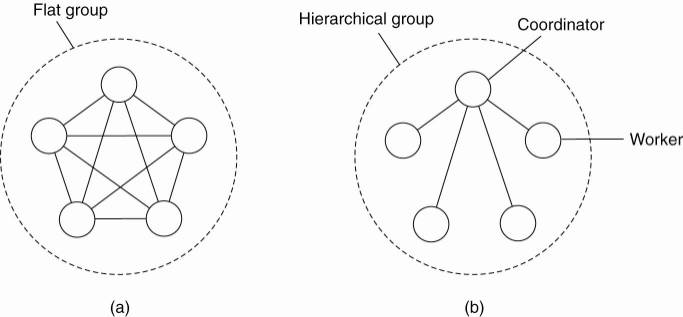
To tolerate a faulty process, organize several identical processes into a group which can be flat or hierarchial group.
a. flat groups: Flat group is good for fault tolerance as information exchange immediately occurs with all group members. All process with in the group have equal roles and control is completely distributed to all process.May impose more overhead as control is completely distributed (hard to implement).
b. hierarchical groups: In hierarchial groups all communication happens through a single coordinator . It is not really fault tolerant and scalable, but relatively easy to implement.
GROUP MEMBERSHIP
Centralized: have a group server to maintain a database for each group and get these requests.Efficient, easy to implement, but single point of failure
Distributed: to join a group, a new process can send a message to all group members that it wishes to join the group (Assume that reliable multicasting is available) .To leave, a process can ideally send a goodbye msg to all, but if it crashes (not just slow) then the others should discover that and remove it from the group!
Techniques for Process Resilience
-
Redundancy:
- Component Redundancy: Deploy multiple instances of critical components so that if one fails, others can take over.
- Example: Using multiple web servers behind a load balancer.
- Data Redundancy: Replicate data across multiple nodes to prevent data loss.
- Example: Replication in databases like MongoDB or Cassandra.
- Component Redundancy: Deploy multiple instances of critical components so that if one fails, others can take over.
-
Replication:
- Active-Active Replication: All replicas actively process requests and synchronize in real-time.
- Example: Multi-master replication in distributed databases.
- Active-Passive Replication: One replica is active while the others are on standby, ready to take over if the active one fails.
- Example: Primary-secondary replication in relational databases.
- Active-Active Replication: All replicas actively process requests and synchronize in real-time.
-
Failover Mechanisms:
- Automatic Failover: Automatically switching to a standby component when the active component fails.
- Example: Using Kubernetes for container orchestration and automatic failover.
- Manual Failover: Administrators manually switch over to a standby component when a failure is detected.
- Example: Manual intervention in legacy systems or in situations where automated failover is not feasible.
- Automatic Failover: Automatically switching to a standby component when the active component fails.
-
Load Balancing:
- Round Robin: Distributing incoming requests sequentially across a pool of servers.
- Example: Simple load balancing with DNS round-robin.
- Least Connections: Directing traffic to the server with the fewest active connections.
- Example: Advanced load balancing strategies in NGINX or HAProxy.
- Round Robin: Distributing incoming requests sequentially across a pool of servers.
-
Checkpointing and Rollback:
- Checkpointing: Periodically saving the state of a process so it can be restored after a failure.
- Example: Checkpointing in distributed computing frameworks like Apache Flink.
- Rollback: Reverting to a previous checkpointed state if a process encounters a fault.
- Example: Using transactional systems that support rollback in case of failure.
- Checkpointing: Periodically saving the state of a process so it can be restored after a failure.