- 1.1 Introduction To Distributed Systems
- 1.2 Examples Of Distributed Systems
- 1.3 Main Characteristics
- 1.4 Advantages And Disadvantages Of Distributed System
- 1.5 Design Goals
- 1.6 Main Problems
- 1.7 Models Of Distributed System
- 1.8 Resource Sharing And The Web Challenges
- 1.9 Types Of Distributed System: Grid, Cluster, Cloud
- Chapter 1 - Slides
- Case Study: Www As Distributed System
- 2.1 Introduction
- 2.2 Communication Between Distributed Objects
- 2.3 Remote Procedure Call
- 2.4 Events And Notifications
- 2.5 Java Rmi Case Study
- 2.6 Introduction To Dfs
- 2.7 File Service Architecture
- 2.8 Sun Network File System
- 2.9 Introduction To Name Services
- 2.10 Name Services And Dns
- 2.11 Directory And Discovery Services
- 2.12 Comparison Of Different Distributed File Systems
- Chapter 2- Slides
- 8.1 Transactions
- 8.2 Nested Transaction
- 8.3 Locks
- 8.4 Optimistic Concurrency Control
- 8.5 Timestamp Ordering
- 8.6 Comparison Of Methods For Concurrency Control
- 8.7 Introduction To Distributed Transactions
- 8.8 Flat And Nested Distributed Transactions
- 8.9 Atomic Commit Protocols
- 8.10 Concurrency Control In Distributed Transactions
- 8.11 Distributed Deadlocks
- 8.12 Transaction Recovery
- 2079 Bhadra-Regular
- 2076 Chaitra, Ashwin- Ioe Old Question Solution, Distributed System
- 2078 Bhadra- Ioe Old Question Solution, Distributed System
- 2069-Chaitra- Ioe Old Question Solution, Distributed System
- 2075- Regular And Back- Ioe Old Question Solution, Distributed System
- 2070-Back- Ioe Old Question Solution, Distributed System
- 2074 Regular/ Back- Ioe Old Question Solution, Distributed System
- 2072 Chaitra / Kartik- Ioe Old Question Solution, Distributed System
- 2079 Bhadra/ 2080 Baishakh- Ioe Old Question Solution, Distributed System
- 2071- Shrawan- Ioe Old Question Solution, Distributed System
- 2071 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Ashadh-Ioe Old Question Solution, Distributed System
DISTRIBUTED SYSTEM NOTES, IOE, BCA,TU
FAULT, FAULT TOLERANCE AND FAULT MANAGEMENT
FAULT
Faults refer to any errors or failures that occur within the system, causing it to deviate from its intended behavior.
TYPES OF FAULT
-
Crash Faults:
- Definition: Occur when a node or a component in the system unexpectedly stops functioning and halts all operations.
- Example: A server suddenly loses power and goes offline.
-
Omission Faults:
- Definition: Happen when a component fails to send or receive messages. This can be further divided into:
- Send Omission: A node fails to send a message.
- Receive Omission: A node fails to receive a message.
- Example: Network congestion causes packets to be dropped, resulting in lost messages.
- Definition: Happen when a component fails to send or receive messages. This can be further divided into:
-
Timing Faults:
- Definition: Occur when the system's timing constraints are violated, either by messages arriving too late or too early.
- Example: A time-sensitive transaction takes longer than the acceptable limit, causing a timeout.
-
Byzantine Faults:
- Definition: These are arbitrary faults where components behave erratically and inconsistently, possibly due to malicious attacks or severe bugs. They can produce incorrect or misleading results.
- Example: A compromised node sends conflicting information to different parts of the system.
-
Network Faults:
- Definition: Issues that arise within the communication network, such as packet loss, network partitioning, and high latency.
- Example: A network partition isolates a subset of nodes from the rest of the system, causing communication failures.
-
Hardware Faults:
- Definition: Failures related to physical components such as servers, storage devices, and network hardware.
- Example: A hard disk crash leads to data loss.
FAULT TOLERANCE
Fault tolerance in distributed systems is the capability of a system to continue functioning properly even when one or more of its components fail. This is a critical feature for distributed systems, as it ensures reliability, availability, and continuous service despite failures.
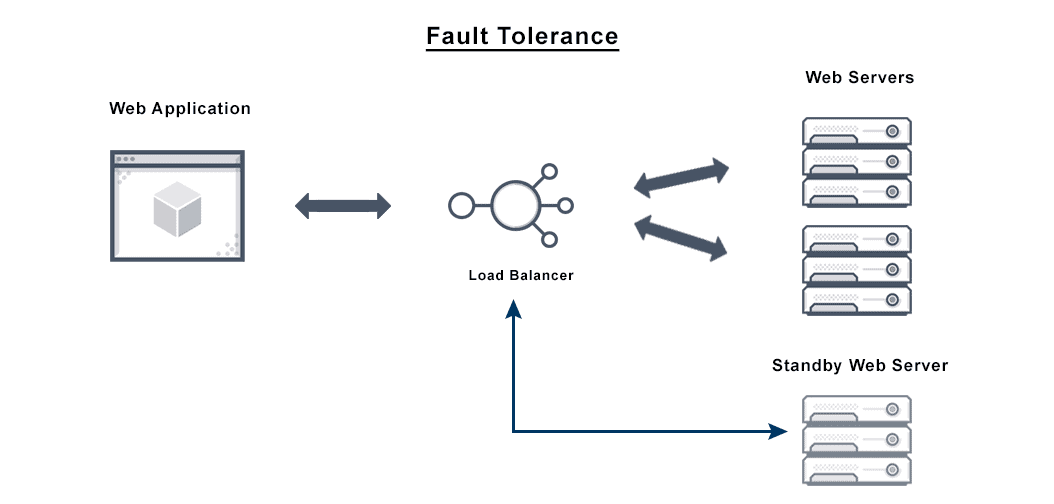
TECHNIQUES FOR FAULT TOLERANCE
-
Redundancy:
- Data Redundancy: Storing copies of data in multiple locations to prevent data loss.
- Component Redundancy: Having multiple instances of critical system components so that if one fails, another can take over.
-
Replication:
- Stateful Replication: Replicating the state of a service or system component across multiple nodes.
- Stateless Replication: Replicating requests and responses, useful for services that do not maintain state.
-
Failover:
- Automatic switching to a standby system or component upon the failure of the primary system.
-
Consensus Protocols:
- Protocols like Paxos, Raft, and Zab ensure that a group of nodes in a distributed system can agree on a single value or course of action even in the presence of failures.
-
Checkpointing and Rollback:
- Saving the state of a system at intervals so that it can be restored to a known good state in case of a failure.
-
Load Balancing:
- Distributing workloads across multiple nodes to ensure no single node becomes a point of failure.
EXAMPLE OF FAULT TOLERANCE SYSTEM
-
Google File System (GFS):
- Utilizes data replication and chunk servers to ensure high availability and fault tolerance.
-
Apache Hadoop:
- Uses data replication across DataNodes to ensure fault tolerance in its distributed file system (HDFS).
-
Amazon Web Services (AWS):
- Employs Availability Zones and regions to ensure services are fault-tolerant by isolating failures.
-
Apache Kafka:
- Uses partitioning and replication of logs to ensure message durability and fault tolerance.
FAULT MANAGEMENT
-
Fault Detection:
- Monitoring and Logging: Continuously monitoring system performance and logging activities to detect anomalies.
- Example: Using tools like Prometheus for monitoring and Elasticsearch for logging.
- Monitoring and Logging: Continuously monitoring system performance and logging activities to detect anomalies.
-
Fault Diagnosis:
- Identifying the underlying cause of a fault by analyzing logs and system states.
- Example: Using tools like Splunk for log analysis.
- Identifying the underlying cause of a fault by analyzing logs and system states.
-
Fault Recovery:
- Automatically switching to a standby component when a primary component fails.
- Example: High-availability clusters using technologies like Pacemaker and Corosync.
- Automatically switching to a standby component when a primary component fails.
-
Fault Prevention:
- Adding extra components that can take over in case of a failure.
- Example: RAID configurations for disk redundancy.
- Adding extra components that can take over in case of a failure.