SCALABILITY GOAL, FAULT TOLERANCE, OPTIMIZATION AND DATA LOCALITY
The two biggest advantages of MapReduce are:
- Parallel Processing:
In MapReduce, we are dividing the job among multiple nodes and each node works with a part of the job simultaneously. So, MapReduce is based on Divide and Conquer paradigm which helps us to process the data using different machines. As the data is processed by multiple machines instead of a single machine in parallel, the time taken to process the data gets reduced by a tremendous amount as shown in the figure below (2).
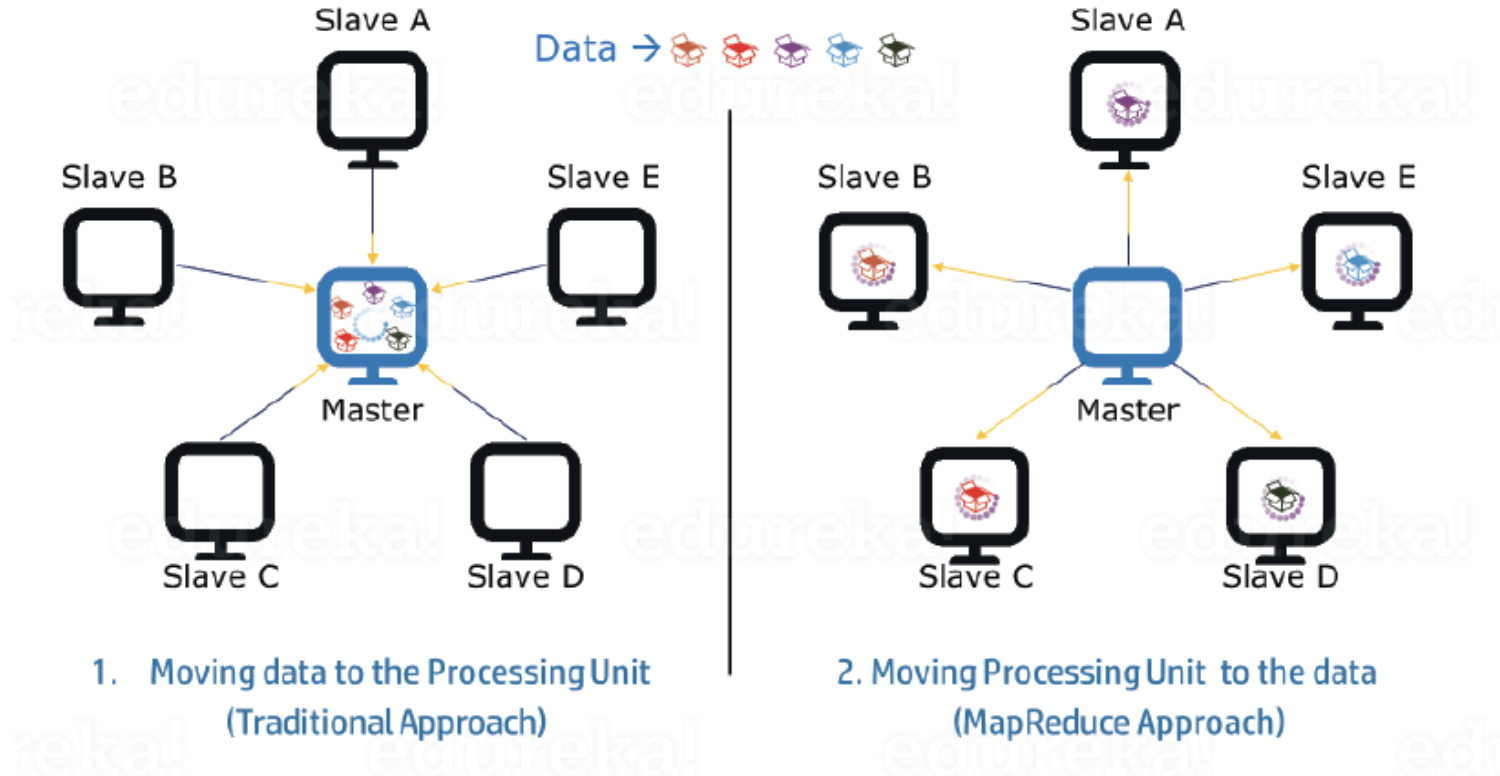
- Data Locality:
Instead of moving data to the processing unit, we are moving the processing unit to the data in the MapReduce Framework. In the traditional system, we used to bring data to the processing unit and process it. But, as the data grew and became very huge, bringing this huge amount of data to the processing unit posed the following issues:
- Moving huge data to processing is costly and deteriorates the network performance.
- Processing takes time as the data is processed by a single unit which becomes the bottleneck.
- The master node can get over-burdened and may fail.
Now, MapReduce allows us to overcome the above issues by bringing the processing unit to the data. So, as you can see in the above image, the data is distributed among multiple nodes where each node processes the part of the data residing on it. This allows us to have the following advantages:
- It is very cost-effective to move the processing unit to the data.
- The processing time is reduced as all the nodes are working with their part of the data in parallel.
- Every node gets a part of the data to process and therefore, there is no chance of a node getting overburdened.
Fault Tolerance:
Fault tolerance is an important aspect of MapReduce as it ensures that the processing can continue even in the event of node failures.
MapReduce provides several mechanisms for fault tolerance, including:
- Data replication: The data is typically stored on multiple nodes in the cluster, which helps to ensure that a copy of the data is always available even if one or more nodes fail.
- Task restart: If a task fails, it is automatically restarted on a different node in the cluster. This helps to ensure that the processing can continue even in the event of node failures.
- Job recovery: If the master node fails, the job can be recovered by a new master node. This helps to ensure that the processing can continue even in the event of master node failures.
- Checkpointing: MapReduce periodically saves its state to disk, which allows it to recover from failures. This helps to ensure that the processing can continue even in the event of node failures.
By combining these mechanisms, MapReduce provides a high degree of fault tolerance, which helps to ensure that large-scale processing can be completed even in the presence of node failures.
References:
1. https://thirdeyedata.ai/hadoop-mapreduce/