- Introduction To Sql
- Features Of Sql
- Queries And Sub Queries
- Set Operations
- Relations (Joined And Derived)
- Queries Under Ddl And Dml Commands
- Embedded Sql
- Views
- Relational Algebra
- Database Modification
- Qbe And Domain Relational Calculus
- Sql Queries Practice Questions
- Relational Algebra Practice Question
Record Organization
In a Database Management System (DBMS), record organization refers to how records (data entries) are stored, accessed, and managed within the database.
Types of Record on basis of Size:
-
Fixed Length Records
Definition:
- Fixed length records have a consistent, unchanging size. Each record in the file uses the same amount of space.
Characteristics:
- Predictable Size: Each record is exactly the same size, making it easy to calculate the position of any record.
- Simplicity: Easy to implement and manage since each record occupies a predefined amount of space.
- Efficiency: Efficient in terms of access speed because the position of a record can be directly calculated (e.g., using simple arithmetic).
Structure of Fixed-Length Records
- Field Sizes:
- Each field within a record has a predefined size.
- All records in the table have the same sequence of fields and the same field sizes.
- Alignment and Padding:
- Fields are often aligned according to their data type, which can lead to padding where empty space is added to maintain alignment.
- Record Header (optional):
- Some systems include a header with metadata, such as a record identifier or status flag (e.g., active, deleted).
Advantages:
- Fast Access: Direct access to records is fast because the position of any record can be computed using its index.
- Simplicity in Management: Easier to manage and update since the structure is uniform.
- Consistent Structure: Each record has the same structure, simplifying parsing and processing.
Disadvantages:
- Wasted Space: If records don’t use all the allocated space, it leads to wasted storage.
- Inflexibility: Difficult to handle records that vary in size without wasting space.
Example:
- Employee records where each record is 100 bytes: If an employee name field is fixed at 50 bytes but some names are shorter, the remaining bytes will be wasted.
2. Variable Length Records
Definition:
- Variable length records have different sizes, depending on the actual data stored in each record.
Variable-length records arise in database systems due to various scenarios:
- Storing multiple record types within a single file.
- Record types that include one or more fields with variable lengths, such as strings (varchar).
- Record types that allow repeating fields, commonly found in some older data models.
Characteristics:
- Flexible Size: Each record can be of a different size, accommodating the actual data without wasting space.
- Complex Management: Requires more complex management techniques to handle varying sizes and keep track of where records start and end.
Implementation of Variable Length Record in Database
a) Length Indicator (Length Prefix)
Each variable-length field is preceded by a length indicator specifying its size.
Implementation Steps:
Define Structure:
- For each field, reserve space for a length indicator followed by the actual data.
Inserting a Record:
- Calculate the length of each variable-length field.
- Store the length followed by the data.
b) Pointer-Based
Pointers reference the location of each field within the record.
Implementation Steps:
Define Pointers:
- Allocate pointers that reference the starting address of each field.
Inserting a Record:
- Store pointers to the start of each field.
- Follow with the actual data.
c) Slotted Page Structure
Pages contain a directory of slots, where each slot points to the beginning of a record within the page.
In the slotted-page structure, a header is present at the starting of each block. This header holds information such as:
- The number of record entries in the header
- No free space remaining in the block
- An array containing the information on the location and size of the records.
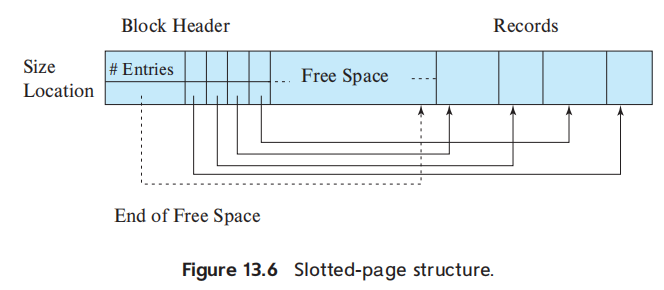
Advantages:
- Efficient Space Usage: More efficient use of space as each record takes up only as much space as needed.
- Flexibility: Can easily handle records of varying sizes, making it suitable for applications with diverse data.
Disadvantages:
- Slower Access: Slower to access specific records because the position of a record is not predictable and may require scanning through previous records.
- Complex Management: Requires additional metadata to keep track of record sizes and locations, which complicates the file structure.
- Fragmentation: Can lead to fragmentation over time as records are added, deleted, and modified, requiring occasional reorganization.
Example:
- Employee records where the name field can vary in length: One record might be 80 bytes while another might be 120 bytes, depending on the length of the employee names and other variable-length fields.
Applications
- Fixed Length Records are often used in situations where speed of access and simplicity are crucial, such as in traditional database systems where record structure doesn’t vary much.
- Variable Length Records are suitable for applications where data size can vary significantly, such as text files, web server logs, or applications with fields that can have widely varying lengths like comments or descriptions.
Types of Record on basis of Organization:
- Heap (Unordered) File Organization:
- Records are placed in the order they are inserted.
- No specific ordering is maintained.
- Efficient for bulk loading and when the order of records is not important.
- Search operations can be slow as it may require a full scan.
- Sequential (Ordered) File Organization:
- Records are stored in a sequential order based on a key field.
- Efficient for range queries and sorted data retrieval.
- Insertions and deletions can be costly as they may require reordering.
- Hash File Organization:
- Records are placed based on a hash function applied to a key field.
- Efficient for exact match queries.
- Not suitable for range queries.
- Clustered File Organization:
- Related records from different tables are stored together.
- Enhances performance for join operations and related queries.
- Can be more complex to maintain.
- Indexing:
- Secondary structure that improves the speed of data retrieval.
- Types include B-trees, B+ trees, and bitmap indexes.
- Can be applied to any of the above file organizations.
Example:
- Heap File: Suitable for applications with high insert volumes and less frequent queries.
- Sequential File: Ideal for applications requiring sorted data or range queries.
- Hash File: Best for applications needing fast exact match lookups.
- Clustered File: Useful in data warehousing and applications with frequent joins.
- Indexed File: Suitable for complex queries requiring quick access to data.