- Introduction To Sql
- Features Of Sql
- Queries And Sub Queries
- Set Operations
- Relations (Joined And Derived)
- Queries Under Ddl And Dml Commands
- Embedded Sql
- Views
- Relational Algebra
- Database Modification
- Qbe And Domain Relational Calculus
- Sql Queries Practice Questions
- Relational Algebra Practice Question
QUERY PROCESSING AND OPTIMIZATION IN DBMS
Query Processing
Query processing involves a three-step procedure that converts a high-level relational SQL query into an equivalent, more efficient lower-level query expressed in relational algebra.
Three steps are :
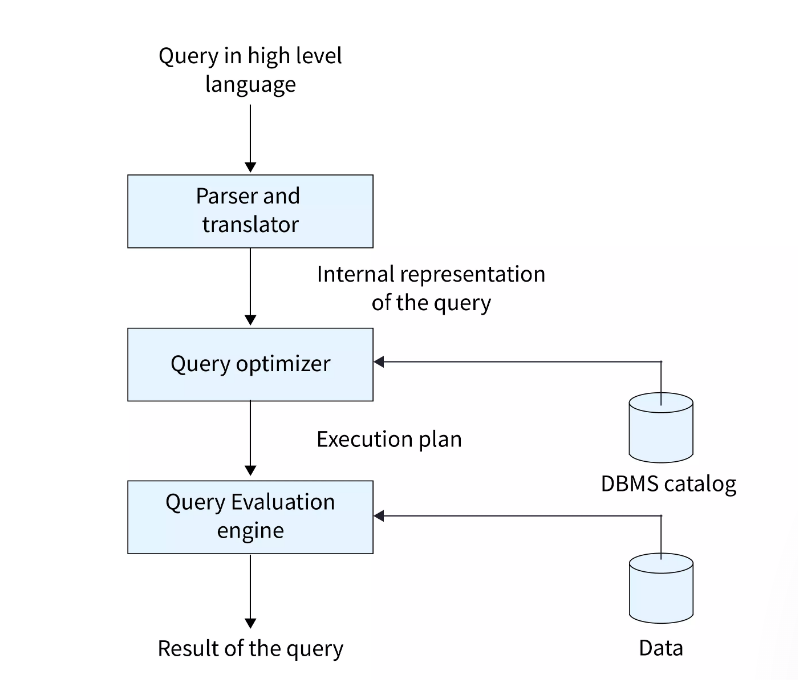
- Parsing and Translation
Whenever a user submits a query in High Level Language like SQL for execution, the parser checks the syntax of the user's query according to the rules of the query language.
SELECT * From EMP WHERE AGE >18;
Here the relation name is EMP which does not match with the original relation name EMPLOYEE.
It also verifies that all the attributes and relation names specified in the query are valid names in the schema of the database being queried.
SELECT PH FROM STU WHERE ID=1;
NO PH ATTRIBUTE IS PRESENT IN DBMS.
After all these checks the query is translated into an equivalent relational algebra expression.
SQL : Select ISBN from BOOK where price >1000;
translated to Relational Expression
Relational Algebra : Π ISBN (σ price<1000(BOOK))
- Query Optimization
There are multiple ways of executing a query known as Execution Strategies.
- Different execution strategies can have different costs.
- It is the responsibility of the query optimizer to choose a least costly execution strategy.
- Query optimizer uses DBMS catalog (metadata stored in the specific table ) to find the best way of evaluating a query.
Query Optimization is the process of choosing a suitable execution
strategy for processing a query.
Suppose we want the price column from the BOOK table , where the price of a book is <1000.
Π price(σ price<1000(BOOK))
Or
σ price (Π price<1000(BOOK))
- Query Evaluation Engine
The query evaluation engine takes the chosen execution strategy as input , executes it and produces the desired result of the query.
QUERY TREE/ PARSE TREE/ OPERATOR TREE/ EXPRESSION TREE
A query tree is a tree data structure that is used to represent relational algebra expressions.
In query tree input relations are represented as the leaf node and relational algebra operations as the internal nodes. The result is at the root node.
When the query tree is executed:
- First the internal node operation is executed whenever its operands are available.
- Then the internal node is replaced by the relation resulting after the execution of the operation.
- The execution terminates when the root is executed and the result of the query is produced.
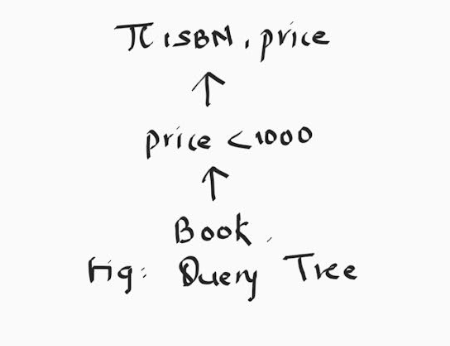
Example 1: Π ISBN ,price (σ price<1000(BOOK))
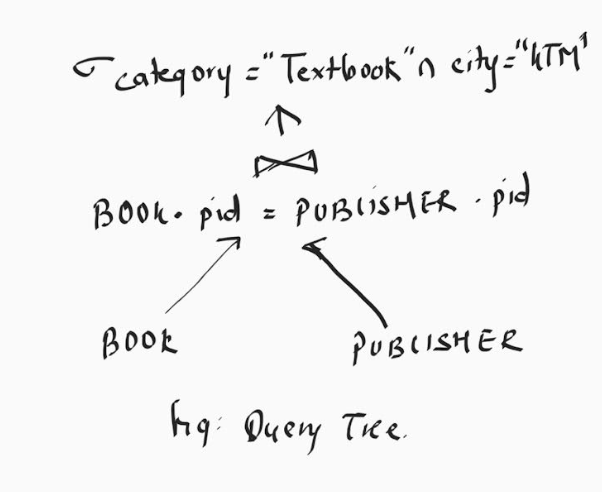
Example 2:
σ (Category)=”Textbook” იCity =” KTM” (BOOK ⋈ BOOK.PID=PUBLISHER.PID(PUBLISHER))
TECHNIQUES OF IMPLEMENTING QUERY OPTIMIZATION
The main aim of Query Optimization is to transform input query into faster equivalent query. There are two techniques of implementing query optimization.
- Cost Based (Physical) Optimization
- Heuristic (Logical) Query Optimization
- Cost Based (Physical) Optimization
A cost based query optimizer assigns costs to different strategies . Then it estimates and compares the cost of executing a query using different execution strategies and chooses the strategy with the lower cost estimate .
The cost of executing query includes:
i) Cost of accessing Secondary Storage: It is the cost of searching , reading and writing disk blocks.
ii) Storage Cost: It is the cost of storing intermediate results.
iii) Computation Cost: It is the cost of performing in-memory operations.
iv) Memory Usage Cost: It is the cost related to the numbers of occupied memory buffers.
v) Communication Cost : It is the cost of communicating results from one site to another.
Issues in Cost Based Optimization
i) Cost function required to assign cost to each operation
ii) Number of execution strategies to be considered not fixed
iii) Sometimes it is time consuming to compare costs.
iv) Does not guarantee finding the best strategy.
v) Not time efficient to consider every possible strategy.
So cost based optimization is a time consuming and expensive optimization technique for implementing query optimization.
b) Heuristic Query Optimization
To reduce cost and computational effort required in Cost based optimization, optimizers apply some heuristics (rules) to find the optimized query execution strategy.
These rules are called heuristics as they usually (but not always) help in reducing the cost of executing a query.
The heuristic query optimizer simply applies these rules without finding out whether the cost is reduced by this transformation. It is based on a query tree.
Heuristic Rules:
The heuristic rules are used as an optimization technique to modify the internal representation of the query. Heuristic Optimization transforms the query tree by using a set of rules (heuristics) that typically improves the performance of input query.
i) Apply select operation before project , join or other binary operations.
ii) Apply Project operation before Join or other binary operations
iii) Select and project operations reduce the size of the file hence should be applied before JOIN or any other operations.
Size of the file resulting from a binary operation like JOIN is very large.
Heuristic query optimizer transforms the initial query tree into the final query tree using equivalence transformation rules. This final query tree is efficient to execute.
IMPLEMENTATION OF INITIAL QUERY TREE TO AN OPTIMAL QUERY TREE USING HEURISTIC QUERY OPTIMIZER.
Given Relational Algebra:
BOOK
|
PID |
ISBN |
CATEGORY |
|
1 |
123 |
textbook |
PUBLISHER
|
PID |
PNAME |
ADDRESS |
|
1 |
ram |
ktm |
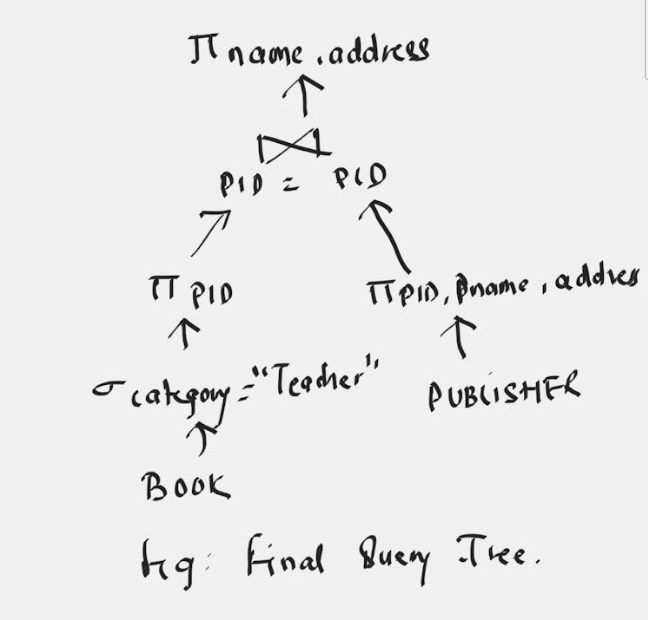
Retrieve the name and address of Publisher , who has published a book in the textbook category.
Πpname, address (σ Category=”Textbook”
(BOOK ⋈ BOOK.PID=PUBLISHER.PID(PUBLISHER)))
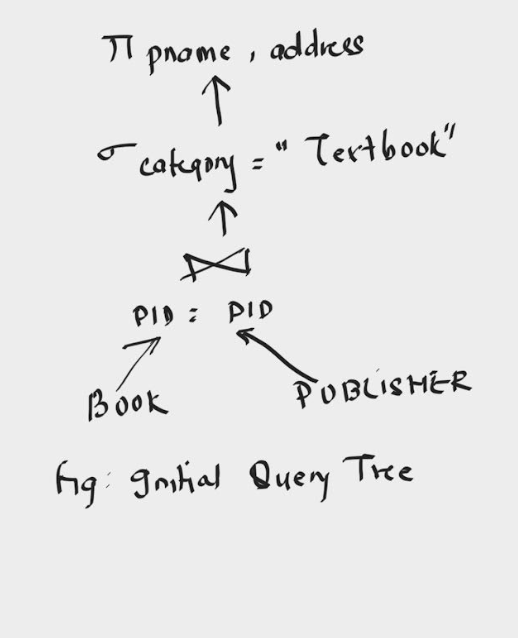
According to the heuristic rule, select operation is performed before project and join.
σ Category=”Textbook” (BOOK )
It reduces the number of tuples
Now we apply project operation before join
ΠPID (σ Category=”Textbook” (BOOK)
And
ΠPID,pname, address (PUBLISHER)
Again the size of the intermediate result can be reduced.
Now apply JOIN operation
Π PID (σ Category=”Textbook” (BOOK)) ⋈ (ΠPID,pname, address (PUBLISHER))
Now extract the desired attributes pname and address from above reduced tuples
Π pname, address((Π PID(σ Category=”Textbook” (BOOK)) ⋈ (Π PID,pname, address (PUBLISHER)))
S the optimal (final ) query tree is :
EQUIVALENCE RULES IN QUERY OPTIMIZATION:


