MapReduce is a programming framework that allows programmers to create programs that process large amounts of unstructured data in parallel across a distributed group of processors.
What is Hadoop?
Hadoop is a Big Data framework designed and deployed by Apache Foundation. It is an open-source software utility that works in the network of computers in parallel to find solutions to Big Data and process it using the MapReduce algorithm.
Google released a paper on MapReduce technology in December 2004. This became the genesis of the Hadoop Processing Model. So, MapReduce is a programming model that allows us to perform parallel and distributed processing on huge data sets.
Map-reduce: The traditional way
Let us understand, when the MapReduce framework was not there, how parallel and distributed processing used to happen in a traditional way. So, let us take an example where I have a weather log containing the daily average temperature of the years from 2000 to 2015. Here, I want to calculate the day having the highest temperature in each year.
So, just like in the traditional way, I will split the data into smaller parts or blocks and store them in different machines. Then, I will find the highest temperature in each part stored in the corresponding machine. At last, I will combine the results received from each of the machines to have the final output.
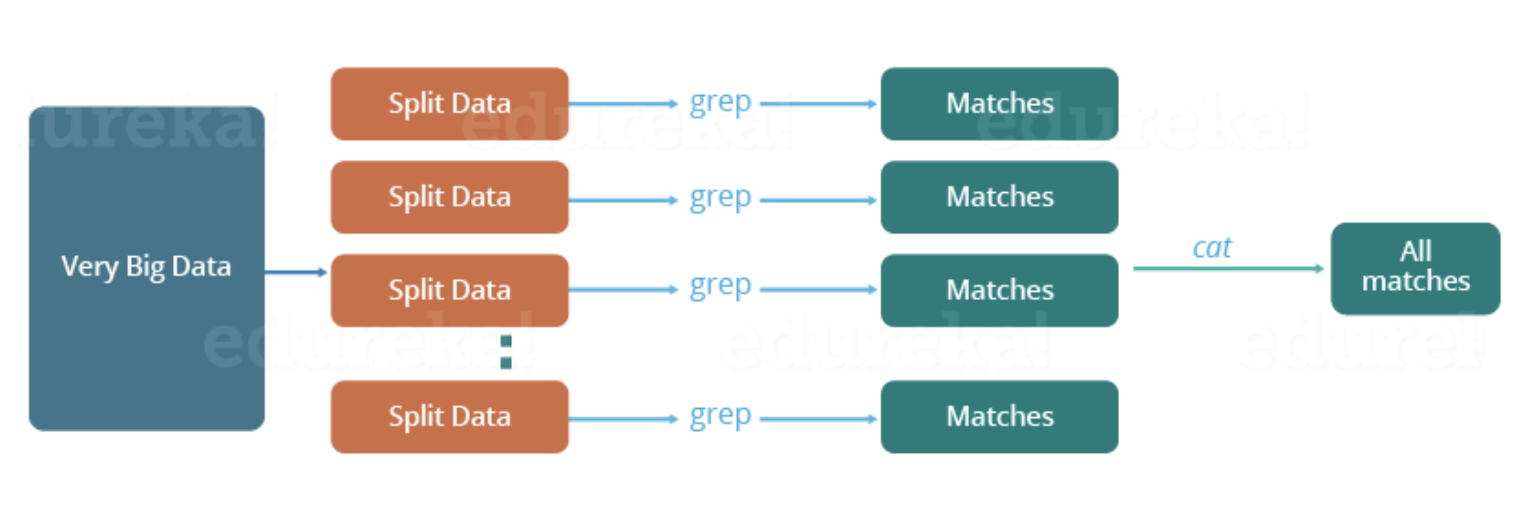
Image Source: Edureka
Let us look at the challenges associated with this traditional approach:
- Critical path problem: It is the amount of time taken to finish the job without delaying the next milestone or actual completion date. So, if, any of the machines delay the job, the whole work gets delayed.
- Reliability problem: What if, any of the machines which are working with a part of data fails? The management of this failover becomes a challenge.
- Equal split issue: How will I divide the data into smaller chunks so that each machine gets even part of data to work with. In other words, how to equally divide the data such that no individual machine is overloaded or underutilized.
- The single split may fail: If any of the machines fail to provide the output, I will not be able to calculate the result. So, there should be a mechanism to ensure this fault tolerance capability of the system.
- Aggregation of the result: There should be a mechanism to aggregate the result generated by each of the machines to produce the final output.
These are the issues encountered, while performing parallel processing of huge data sets when using traditional approaches.
To overcome these issues, we have the MapReduce framework which allows us to perform such parallel computations without bothering about the issues like reliability, fault tolerance etc. Therefore, MapReduce gives you the flexibility to write code logic without caring about the design issues of the system.
Once we write an application in the MapReduce form, scaling the application to run over hundreds, thousands, or even tens of thousands of machines in a cluster is merely a configuration change. This simple scalability is what has attracted many programmers to use the MapReduce model.
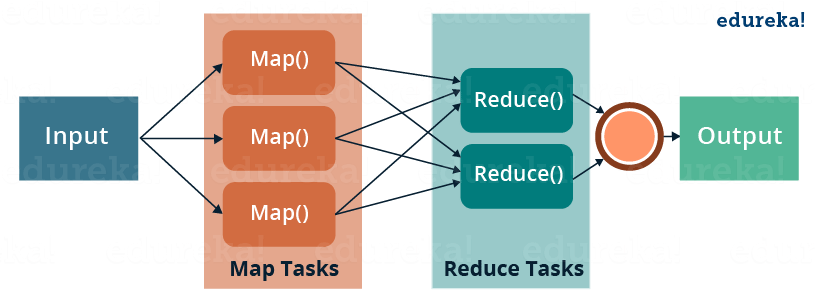
Image Source: Edureka
MapReduce is a programming framework that allows us to perform distributed and parallel processing on large data sets in a distributed environment.
- MapReduce consists of two distinct tasks – Map and Reduce.
- As the name MapReduce suggests, the reducer phase takes place after the mapper phase has been completed.
- So, the first is the map job, where a block of data is read and processed to produce key-value pairs as intermediate outputs.
- The output of a Mapper or map job (key-value pairs) is input to the Reducer.
- The reducer receives the key-value pair from multiple map jobs.
- Then, the reducer aggregates those intermediate data tuples (intermediate key-value pair) into a smaller set of tuples or key-value pairs which is the final output.
MapReduce majorly has the following three Classes. They are,
Mapper Class
The first stage in Data Processing using MapReduce is the Mapper Class. Here, RecordReader processes each Input record and generates the respective key-value pair. Hadoop’s Mapper store saves this intermediate data into the local disk.
- Input Split
It is the logical representation of data. It represents a block of work that contains a single map task in the MapReduce Program.
- RecordReader
It interacts with the Input split and converts the obtained data in the form of Key-Value Pairs.
Reducer Class
The Intermediate output generated from the mapper is fed to the reducer which processes it and generates the final output which is then saved in the HDFS.
Driver Class
The major component in a MapReduce job is a Driver Class. It is responsible for setting up a MapReduce Job to run-in Hadoop. We specify the names of Mapper and Reducer Classes long with data types and their respective job names.
References:
1. https://www.edureka.co/blog/mapreduce-tutorial/