Background
Hadoop is an open-source, distributed computing system that is used to store and process large datasets across a cluster of commodity hardware. It was originally developed by Doug Cutting and Mike Cafarella in 2005, and it was named after a toy elephant that Cutting's son owned.
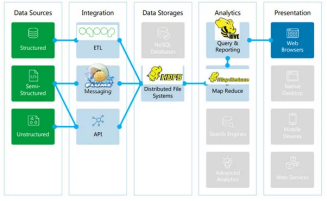
Hadoop is designed to handle large amounts of structured, semi-structured, and unstructured data. It can store and process petabytes of data across thousands of commodity servers, providing both scalability and fault tolerance. Hadoop includes two core components: the Hadoop Distributed File System (HDFS) and the MapReduce programming model.
Hadoop also includes several other components that build on top of HDFS and MapReduce, including Hadoop YARN, Hadoop Common, Hadoop Oozie, Hadoop Pig, Hadoop Hive, and Hadoop Spark. These components provide additional functionality for data processing, management, and analysis.
Hadoop is a powerful and flexible framework for handling large and complex datasets. Its scalability, fault tolerance, and ability to handle different types of data make it a popular choice for organizations across industries, including finance, healthcare, and e-commerce.
History
Prior to the development of Hadoop, there was a growing need for a more efficient way to store and process large datasets. Traditional relational database systems were not designed to handle the enormous amount of data generated by modern applications. This led to the development of distributed file systems and parallel processing frameworks.
One of the earliest distributed file systems was the Network File System (NFS), which was developed in the 1980s by Sun Microsystems. NFS allowed multiple computers to share a single file system, which made it easier to store and access large datasets.
Another early distributed file system was the Andrew File System (AFS), which was developed at Carnegie Mellon University in the 1980s. AFS was designed to provide a distributed file system that was transparent to users, meaning that they did not need to know where their files were physically stored.
Parallel processing frameworks were also developed in the 1980s and 1990s. One of the earliest was the Parallel Virtual Machine (PVM), which was developed by a group of researchers at Oak Ridge National Laboratory in 1989. PVM allowed multiple computers to work together to solve a single computational problem.
Another early parallel processing framework was the Message Passing Interface (MPI), which was developed in the 1990s. MPI was designed to provide a standard interface for message passing between different parallel processing systems.
In the late 1990s and early 2000s, companies such as Google and Yahoo! were dealing with enormous amounts of data that needed to be processed quickly and efficiently. Traditional relational database systems were not capable of handling this data, so these companies began developing their own distributed computing systems.
Google developed a distributed file system called the Google File System (GFS) in the early 2000s. GFS was designed to store and manage massive amounts of data across a large cluster of commodity hardware. It was also designed to be fault-tolerant, meaning that it could continue to operate even if some of the nodes in the cluster failed.
Google also developed a programming model called MapReduce, which was used to process data in parallel across the cluster. MapReduce allowed complex data processing tasks to be broken down into smaller, more manageable pieces, which could then be processed in parallel across the cluster.
Yahoo! also began developing its own distributed computing system in the mid-2000s. Yahoo!'s system was based on the Google File System and MapReduce, but it also included a number of other components, such as a job scheduler and a distributed coordination system.

The Hadoop project was initially developed by Doug Cutting and Mike Cafarella in 2003, as we mentioned earlier. They were working on an open-source search engine called Nutch, which was designed to index and search the World Wide Web. However, they quickly realized that they needed a way to store and process the massive amounts of data they were dealing with.
Cutting and Cafarella were inspired by GFS and MapReduce and began to experiment with adapting them to their search engine project. They created an open-source implementation of MapReduce and GFS called Hadoop, which they released as an Apache project in 2006.
The initial release of Hadoop was relatively simple, consisting of just Hadoop Distributed File System (HDFS) and MapReduce. However, over time, Hadoop has evolved and grown significantly, with the addition of many new features and components.
In 2008, Yahoo became one of the largest contributors to the Hadoop project, dedicating a team of engineers to work on Hadoop full-time. This helped to accelerate the development of Hadoop and contributed to its widespread adoption. In 2009, Hadoop 0.20 was released, which included significant improvements to HDFS, as well as the addition of new features such as support for append operations and improved fault tolerance and the current version of Hadoop released up to now (date of the case study) is 2.10.
Problem Statement
Before the development of Hadoop, traditional distributed systems had several issues that made it difficult to process large amounts of data.
Scalability: Traditional distributed systems were not designed to handle the scale of data that is generated in today's digital world. These systems often had a fixed architecture, which made it difficult to scale the system as the volume of data increased. Additionally, traditional distributed systems were often built using proprietary hardware and software, which made them expensive to scale.
Fault Tolerance: Another issue with traditional distributed systems was fault tolerance. These systems often had a single point of failure, which meant that if a node in the system failed, the entire system would go down. Additionally, traditional distributed systems were often not designed to handle the high levels of data redundancy that are necessary for fault tolerance.
Data Processing: Traditional distributed systems were often designed for specific types of data processing, such as transaction processing or batch processing. These systems were not well-suited for processing large amounts of unstructured data, such as social media data or sensor data.
Cost: Traditional distributed systems were often expensive to build and maintain. These systems required specialized hardware and software, which made them prohibitively expensive for many organizations.
Complexity: Traditional distributed systems were often complex and difficult to manage. These systems required specialized skills and expertise, which made it difficult for many organizations to adopt them.
Overall, the issues with traditional distributed systems made it difficult to process large amounts of data. Hadoop was developed to address these issues by providing a scalable, fault-tolerant, and cost-effective platform for processing large datasets.
Hadoop's distributed architecture, fault tolerance, and flexibility have made it a popular platform for big data processing across industries and applications.
Overview
Architecture
The Hadoop architecture is designed to be distributed and fault-tolerant. It consists of two main components: Hadoop Distributed File System (HDFS) and MapReduce along with different components as shown:
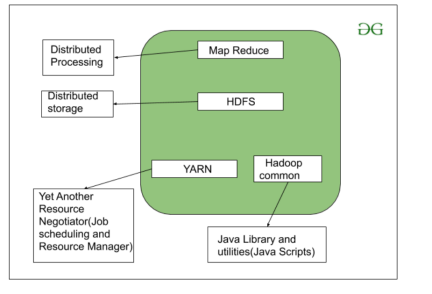
a. HDFS:
HDFS is a distributed file system that is designed to store large files across multiple machines. It is inspired by the Google File System (GFS) and is based on the concept of blocks. HDFS breaks down large files into smaller blocks, which are then distributed across multiple machines in the cluster. Each block is replicated across multiple machines for fault tolerance.
b. MapReduce:
MapReduce is a programming model for processing large datasets in a distributed environment. It consists of two main phases: Map and Reduce. In the Map phase, the input data is processed and transformed into a set of key-value pairs. In the Reduce phase, the key-value pairs are aggregated and combined to produce the final output.
c. YARN (Yet Another Resource Negotiator):
YARN is a resource manager for Hadoop that is responsible for managing resources in the cluster. It provides a framework for scheduling and allocating resources for different applications running in the cluster.
d. Hadoop Common:
Hadoop Common is a set of libraries and utilities that are used by all the other components in Hadoop. It includes common utilities for handling input/output, serialization, and networking.
e. Hadoop Distributed Copy (DistCP):
DistCP is a utility for copying large amounts of data between Hadoop clusters. It is designed to be scalable and fault-tolerant, and it can handle data transfers of several terabytes.
f. Hadoop Streaming:
Hadoop Streaming is a utility for processing non-Java applications in Hadoop. It allows users to write MapReduce jobs using any programming language that can read from standard input and write to standard output.
g. Hadoop Security:
Hadoop Security provides a framework for securing the Hadoop cluster. It includes features such as authentication, authorization, and encryption. HDFS
The Hadoop Distributed File System (HDFS) is a distributed file system designed to store and process large datasets across multiple machines. It is inspired by the Google File System (GFS) and is based on the concept of blocks. HDFS breaks down large files into smaller blocks, which are then distributed across multiple machines in the cluster. Each block is replicated across multiple machines for fault tolerance. HDFS also includes a Namenode, which is responsible for managing the metadata of the files in the system, and multiple Datanodes, which are responsible for storing the actual data. The HDFS architecture consists of two main components: Namenode and Datanode.
a. Namenode
The Namenode is the master node in the HDFS architecture. It is responsible for managing the metadata of the files in the system. The metadata includes information such as file names, file sizes, block locations, and permissions. The Namenode maintains this information in a data structure called the namespace. The namespace is stored in memory and is periodically saved to disk to prevent data loss.
b. Datanode
The Datanode is the worker node in the HDFS architecture. It is responsible for storing the actual data blocks. Each Datanode stores a subset of the data blocks in the system. The Datanode periodically sends a heartbeat signal to the Namenode to indicate that it is still alive. The Namenode uses this information to keep track of the health of the Datanodes in the cluster.
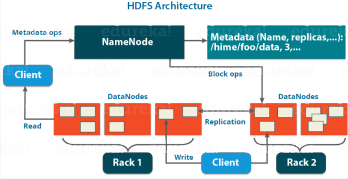
Data replication is a key feature of HDFS. Replication ensures that the data is available even if some of the machines in the cluster fail. Each block in HDFS is replicated across multiple machines. By default, HDFS replicates each block three times. This means that each block is stored on three different machines in the cluster. The replication factor can be configured depending on the size of the cluster and the level of fault tolerance required.
When a client writes data to HDFS, the data is first written to the local disk of the Datanode. The Datanode then replicates the data to other Data Nodes in the cluster. The Namenode keeps track of the locations of all the replicas of each block in the system. When a client reads data from HDFS, the Namenode returns the locations of all the replicas of the requested block. The client then reads the data from the nearest replica.
MapReduce
The MapReduce programming model is a programming model for processing large datasets in a distributed environment. It consists of two main phases: Map and Reduce. In the Map phase, the input data is processed and transformed into a set of key-value pairs. In the Reduce phase, the key-value pairs are aggregated and combined to produce the final output.
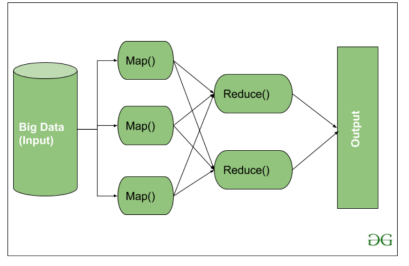
The MapReduce architecture consists of two main components: JobTracker and TaskTracker.
a. JobTracker
The JobTracker is the master node in the MapReduce architecture. It is responsible for scheduling and coordinating MapReduce jobs. When a client submits a MapReduce job, the JobTracker assigns tasks to the TaskTrackers in the cluster. The JobTracker also monitors the progress of the job and handles failures.
b. TaskTracker
The TaskTracker is the worker node in the MapReduce architecture. It is responsible for executing the Map and Reduce tasks assigned to it by the JobTracker. The TaskTracker receives input data from HDFS and runs the Map and Reduce functions on that data. The TaskTracker periodically sends a heartbeat signal to the JobTracker to indicate that it is still alive. The JobTracker uses this information to keep track of the health of the TaskTrackers in the cluster. The workflow is divided into several steps:
i. Input data is divided into input splits based on the size of the input data and the number of nodes in the cluster.
ii. The JobTracker assigns Map tasks to the TaskTrackers in the cluster. Each Map task processes an input split and produces a set of intermediate key-value pairs.
iii.The intermediate key-value pairs produced by the Map tasks are sorted and partitioned based on the key.
iv. The JobTracker assigns Reduce tasks to the TaskTrackers in the cluster. Each Reduce task processes a subset of the intermediate key-value pairs and produces a set of final key-value pairs.
v. The final key-value pairs produced by the Reduce tasks are written to HDFS.
Implementation
Ecosystem
The implementation requires the whole Hadoop Ecosystem to be involved from data access and collection to data storage. Data processing and data storage is handled by Hadoop Core systems but there are other tools along with the core that organizations use to effectively handle big data operations.
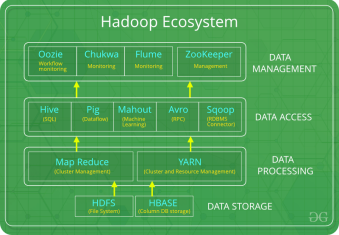
Organizations can implement the Hadoop ecosystem in a number of ways, depending on their specific requirements and use cases. The following are the steps that organizations can follow to implement the Hadoop ecosystem:
a. Define the use case: The first step in implementing the Hadoop ecosystem is to define the use case for which it will be used. Organizations should identify the specific data processing, storage, and analytics requirements that they need to address.
b. Design the architecture: Once the use case has been defined, organizations should design the architecture for the Hadoop cluster. The architecture should take into account the specific requirements of the use case and should include the appropriate tools and frameworks from the Hadoop ecosystem.
c. Install and configure the Hadoop cluster: Organizations should install and configure the Hadoop cluster based on the designed architecture. This involves setting up the HDFS, MapReduce, and YARN components, as well as installing and configuring the necessary tools and frameworks from the Hadoop ecosystem.
d. Ingest data: Once the Hadoop cluster has been set up, organizations can start ingesting data into the system. This can involve collecting data from various sources using tools like Flume and Kafka, or importing data from relational databases using Sqoop.
e. Process data: Once the data has been ingested into the Hadoop cluster, organizations can start processing it using tools like Hive, Pig, and Spark. These tools enable organizations to perform a wide range of data processing tasks, such as data cleansing, aggregation, and analysis.
f. Store data: As data is processed, it can be stored in HDFS or in other data stores like HBase. Hadoop provides a highly scalable and fault-tolerant storage system that can handle large volumes of data.
g. Analyze data: Once the data has been processed and stored, organizations can analyze it using tools like Hive, Pig, and Spark. These tools enable organizations to perform complex analytics tasks on large volumes of data, such as predictive modeling, machine learning, and data visualization.
h. Monitor and manage the cluster: As the Hadoop cluster is used to process and analyze large volumes of data, it is important to monitor and manage the cluster to ensure optimal performance and reliability. Tools like Oozie and ZooKeeper can be used to manage workflows and coordinate distributed applications, while monitoring tools like Nagios and Ganglia can be used to monitor the health of the Hadoop cluster.
Case of Study: Facebook
One of the companies that has extensively used Hadoop is Facebook. In this case study, we will explore how Facebook has leveraged Hadoop to process and analyze its massive data sets.
Facebook is one of the largest social media platforms in the world, with over 2.8 billion monthly active users. To manage the enormous amount of data generated by its users, Facebook has implemented Hadoop as its big data processing platform. Facebook has been using Hadoop since 2007 to process and analyze its massive data sets.
Facebook uses Hadoop extensively for various purposes such as data analysis, machine learning, and log processing. The following are the details of the implementation of Hadoop at Facebook.
a. Hadoop Distribution: Facebook uses its own Hadoop distribution called "Facebook Hadoop" or "Hive/Hadoop" which is a customized version of Apache Hadoop. The customization includes several performance improvements and additional features that are not available in the standard Hadoop distribution.
b. Data Storage: Facebook stores its data in HDFS (Hadoop Distributed File System) and HBase, which is a distributed NoSQL database built on top of Hadoop. Facebook uses HDFS to store large data sets such as user profiles, photos, and videos, and uses HBase to store real-time data such as user activity logs.
c. Data Processing: Facebook uses the MapReduce processing framework for batch processing of large data sets. Facebook's implementation of MapReduce includes several optimizations such as dynamic task scheduling, speculative execution, and customized partitioning algorithms that improve the performance of data processing.
d. Real-Time Processing: In addition to batch processing, Facebook also uses Apache Kafka, Apache Storm, and Apache Samza for real-time processing of data. These tools provide real-time data processing capabilities for tasks such as monitoring user activity and serving real-time content to users.
e. Machine Learning: Facebook uses Hadoop for machine learning tasks such as training and deploying machine learning models. Facebook's implementation of machine learning on Hadoop includes several customizations and optimizations that improve the performance of machine learning tasks.
f. Analytics: Facebook uses several analytics tools such as Apache Hive, Apache Impala, and Presto to query and analyze large data sets stored in Hadoop. These tools provide SQL-like interfaces for querying Hadoop data and enable ad-hoc analysis of large data sets.
g. Custom Tools: Facebook has developed several custom tools on top of Hadoop for specific use cases such as data compression, data encryption, and data indexing. These tools enable Facebook to process and analyze large data sets efficiently and securely.
Facebook's implementation of Hadoop is one of the largest in the world, with over 100 petabytes of data stored in Hadoop clusters. Facebook has customized Hadoop to suit its specific requirements and has optimized it for performance, scalability, and reliability.
Analysis
Use Cases
We discuss use cases of hadoop taking a case of study at Facebook. Here are the lists of use cases at facebook:
a. Ad Targeting:
Facebook uses Hadoop for ad targeting, which involves selecting the most relevant ads to show to users based on their interests, demographics, and behaviors. Facebook's ad targeting system uses a combination of machine learning algorithms and human input to select the most relevant ads for each user.
Hadoop is used to store and process massive amounts of data related to users' interests, behaviors, and demographics. The data is processed using Hadoop's MapReduce framework to generate user profiles, which are then used by the ad targeting system to select the most relevant ads.
b. Fraud Detection
Facebook uses Hadoop for fraud detection, which involves identifying and preventing fraudulent activity on the platform. Fraudulent activity can take many forms, such as fake accounts, click fraud, and spam.
Hadoop is used to process and analyze massive amounts of data related to user activity, such as log files and clickstream data. The data is processed using Hadoop's MapReduce framework to identify patterns and anomalies that may indicate fraudulent activity. Machine learning algorithms are also used to detect and prevent fraud, and Hadoop is used to train and deploy these algorithms.
c. Content Ranking
Facebook uses Hadoop for content ranking, which involves selecting and ranking the most relevant content for each user's news feed. The ranking algorithm takes into account a wide range of factors, such as user engagement, relevance, freshness, and diversity.
Hadoop is used to process and analyze massive amounts of data related to user engagement, such as likes, shares, comments, and clicks. The data is processed using Hadoop's MapReduce framework to generate user profiles, which are then used by the content ranking algorithm to select and rank the most relevant content. d. User Behavior Analysis
Facebook uses Hadoop for user behavior analysis, which involves understanding how users interact with the platform, what features they use, and how they engage with content. User behavior analysis is important for improving user experience, identifying trends, and optimizing the platform's features and functionalities.
Hadoop is used to store and process massive amounts of data related to user behavior, such as log files, clickstream data, and user activity data. The data is processed using Hadoop's MapReduce framework to identify patterns and trends in user behavior. Machine learning algorithms are also used to analyze user behavior and provide insights for improving user experience.
Challenges
While Hadoop has many benefits for processing and analyzing big data, there are also a number of challenges associated with using Hadoop at scale. Some of the key challenges that Facebook has faced with Hadoop include:
a. Data Volume and Velocity
As one of the largest social media platforms in the world, Facebook generates massive amounts of data every day. This data is generated at a high velocity, with millions of users interacting with the platform in real-time. Managing and processing this volume and velocity of data requires a highly scalable and fault-tolerant infrastructure.
To address this challenge, Facebook has developed a number of optimizations and customizations to Hadoop, such as using Hadoop's Distributed Cache for caching frequently accessed data, optimizing MapReduce jobs for parallelism, and using custom compression algorithms for storing and processing data.
b. Resource Management
Hadoop requires a significant amount of resources, such as CPU, memory, and disk space, to store and process data. Managing these resources efficiently is critical for ensuring optimal performance and cost-effectiveness.
To address this challenge, Facebook has developed a number of resource management tools and techniques, such as using Hadoop's Fair Scheduler for job scheduling, using YARN for resource allocation and management, and using custom monitoring tools for tracking resource usage and performance.
c. Data Security
As a social network, Facebook collects and stores sensitive user data, such as personal information, messages, and photos. Protecting this data from unauthorized access and misuse is critical for ensuring user privacy and trust.
To address this challenge, Facebook has developed a number of data security measures, such as using Kerberos for authentication and authorization, using encryption for data at rest and in transit, and using custom access control policies for controlling data access and usage.
Conclusion
In conclusion, the implementation of the Hadoop system by different organizations has brought about significant benefits to various industries, including finance, healthcare, e-commerce, and more. Hadoop's ability to process large amounts of unstructured data quickly and cost-effectively has revolutionized the way organizations approach big data analytics.
By adopting Hadoop, organizations have been able to gain valuable insights from their data, enabling them to make informed business decisions and improve their operational efficiency. Additionally, Hadoop's distributed computing architecture allows for scalability, which means that organizations can easily expand their infrastructure as their data needs grow.
However, the implementation of Hadoop is not without its challenges. Organizations may struggle with the complexity of the system, the shortage of skilled professionals, and the cost of maintaining the infrastructure. Therefore, it is crucial for organizations to carefully evaluate their business needs before implementing Hadoop and to work with experienced professionals to ensure successful implementation.
Overall, the implementation of Hadoop by different organizations has shown that the system has the potential to transform the way organizations approach big data analytics. With careful planning and implementation, Hadoop can help organizations gain valuable insights from their data and stay ahead of their competition in today's data-driven business environment.
References
● Apache Hadoop: The official website for Apache Hadoop, which includes documentation, downloads, and other resources. https://hadoop.apache.org/
● Hadoop MapReduce Tutorial: A tutorial on MapReduce from the Hadoop website. https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client core/MapReduceTutorial.html
● Hadoop Distributed File System: The official documentation for HDFS, which includes an overview, architecture, and more.
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.ht ml
● Introduction to Hadoop : GeeksforGeeks
https://www.geeksforgeeks.org/hadoop-an-introduction/
● Hadoop Tutorial: A comprehensive tutorial on Hadoop from TutorialsPoint, which covers MapReduce, HDFS, and other components.
https://www.tutorialspoint.com/hadoop/index.htm
● MapReduce Tutorial: A tutorial on MapReduce from MapR, which includes examples and exercises.
https://mapr.com/developercentral/developer-resources/tutorials/hadoop-tutorial-mapreduce example/