Indexing with Lucene
Apache Lucene is an open-source, high-performance, scalable data retrieval engine with powerful data retrieval capabilities. Lucene has been developed over many years, providing more powerful features and an increasingly refined architecture. It currently supports full-text indexing as well as providing many other types of indexing to satisfy the requirements of different types of query.
Many open-source projects are based on Lucene. The best known are Elasticsearch and Solr. If we compare Elasticsearch and Solr to an exquisitely designed, high-performance sports car, then Lucene would be the engine providing the powerful motive force. We need to study its engine in minute detail to tune the car to give a faster and more stable ride.
Lucene officially summarizes its advantages in several points:
- Scalable, High-Performance Indexing
- Powerful, Accurate and Efficient Search Algorithms
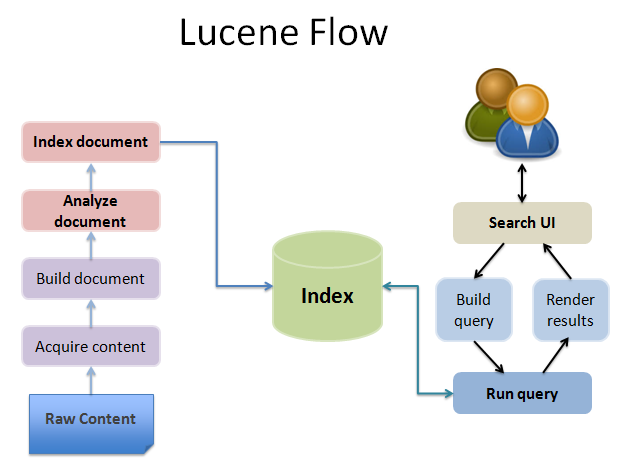
How do search applications work?
Source: Image
A search application performs all or few following operations:
- Acquire Raw Content
The first step of any search application is to collect the target contents on which search application is to be conducted.
- Build the document
The next step is to build the document(s) from the raw content, which the search application can understand and interpret easily.
- Analyze the document
Before the indexing process starts, the document is to be analyzed as to which part of the text is a candidate to be indexed. This process is where the document is analyzed.
- Indexing the document
Once documents are built and analyzed, the next step is to index them so that this document can be retrieved based on certain keys instead of the entire content of the document. Indexing process is similar to indexes at the end of a book where common words are shown with their page numbers so that these words can be tracked quickly instead of searching the complete book.
- User Interface for Search
Once a database of indexes is ready then the application can make any search. To facilitate a user to make a search, the application must provide a user a mean or a user interface where a user can enter text and start the search process.
- Build Query
Once a user makes a request to search a text, the application should prepare a Query object using that text which can be used to inquire index database to get the relevant details.
- Search Query
Using a query object, the index database is then checked to get the relevant details and the content documents.
- Render Results
Once the result is received, the application should decide on how to show the results to the user using User Interface. How much information is to be shown at first look and so on.
Lucene's Role in Search Application
Lucene plays a role in steps 2 to step 7 mentioned above and provides classes to do the required operations. In a nutshell, Lucene is the heart of any search application and provides vital operations pertaining to indexing and searching. Acquiring contents and displaying the results is left for the application part to handle.
Lucene - Indexing Process
Indexing process is one of the core functions provided by Lucene. Following diagram illustrates the indexing process and use of classes. IndexWriter is the most important and core component of the indexing process.
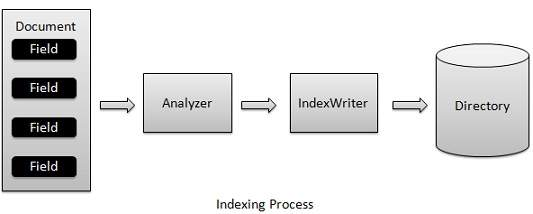
We add Document(s) containing Field(s) to IndexWriter which analyzes the Document(s) using the Analyzer and then creates/open/edit indexes as required and store/update them in a Directory. IndexWriter is used to update or create indexes. It is not used to read indexes.
Creating an Index
The first step in implementing full-text searching with Lucene is to build an index. Here's a simple attempt to diagram how the Lucene classes go together when you create an index:
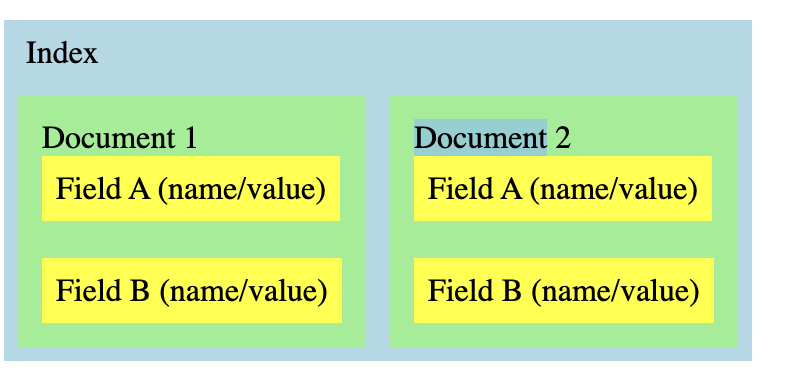
At the heart of Lucene is an Index. You pump your data into the Index, then do searches on the Index to get results out. Document objects are stored in the Index, and it is your job to "convert" your data into Document objects and store them to the Index. That is, you read in each data file (or Web document, database tuple or whatever), instantiate a Document for it, break down the data into chunks and store the chunks in the Document as Field objects (a name/value pair). When you're done building a Document, you write it to the Index using the IndexWriter.
IndexWriter Class: Creating Index
To create an index, the first thing that need to do is to create an IndexWriter object. The IndexWriter object is used to create the index and to add new index entries (i.e., Documents) to this index. You can create an IndexWriter as follows:
|
Directory indexDir = FSDirectory.open(new File("index-directory")); |
Analyzer Class: Parsing the Documents
Most likely, the data that you want to index by Lucene is plain text English. The job of Analyzer is to "parse" each field of your data into indexable "tokens" or keywords. Several types of analyzers are provided out of the box. Table 1 shows some of the more interesting ones.

{kind=link}
Adding a Document/object to Index
Now you need to index your documents or business objects. To index an object, you use the Lucene Document class, to which you add the fields that you want indexed. As we briefly mentioned before, a Lucene Document is basically a container for a set of indexed fields. This is best illustrated by an example:
|
Document doc = new Document(); |
In the above example, we add two fields, "id" and "description", with the respective values "Hotel-1345" and "A beautiful hotel" to the document.
More precisely, to add a field to a document, you create a new instance of the Field class, which can be either a StringField or a TextField (the difference between the two will be explained shortly). A field object takes the following three parameters:
- Field name: This is the name of the field. In the above example, they are "id" and "description".
- Field value: This is the value of the field. In the above example, they are "Hotel-1345" and "A beautiful hotel". A value can be a String like our example or a Reader if the object to be indexed is a file.
- Storage flag: The third parameter specifies whether the actual value of the field needs to be stored in the lucene index or it can be discarded after it is indexed. Storing the value is useful if you need the value later, like you want to display it in the search result list or you use the value to look up a tuple from a database table, for example. If the value must be stored, use Field.Store.YES. You can also use Field.Store.COMPRESS for large documents or binary value fields. If you don't need to store the value, use Field.Store.NO.
For our hotel example, we just want some fairly simple full-text searching. So we add the following fields:
- The hotel identifier (or the key to the hotel tuple), so we can retrieve the corresponding hotel object from the database later once we obtain the query result list from the Lucene index.
- The hotel name, which we need to display in the query result lists.
- The hotel city, if we need to display this information in the query result lists.
- Composite text containing the important fields of the Hotel object:
- Hotel name
- Hotel city
- Hotel description
We want full-text indexing on this field. We don't need to display the indexed text in the query results, so we use Field.Store.NO to save index space.
Here's the method in the Indexer class in our demo that indexes a given hotel:
|
public void indexHotel(Hotel hotel) throws IOException { |