- Pci Dss
- Sox
- Hippa,
- Evaluating Systems
- Evaluating Systems, Goals Of Evaluating Systems
- Tcsec
- Itsec
- Fips
- Common Criteria
- Sse-Cmm
- Law And Information Security
- Historical Evolution Of Computer Related Law In The Us
- Privacy Law And Its Significance To Information Security
- The Uk Dpa And The Eu Gdpr
- Eta Of Nepal
Hash Function
A hash function is a unique identifier for any given piece of content. It’s also a process that takes plaintext data of any size and converts it into a unique ciphertext of a specific length.
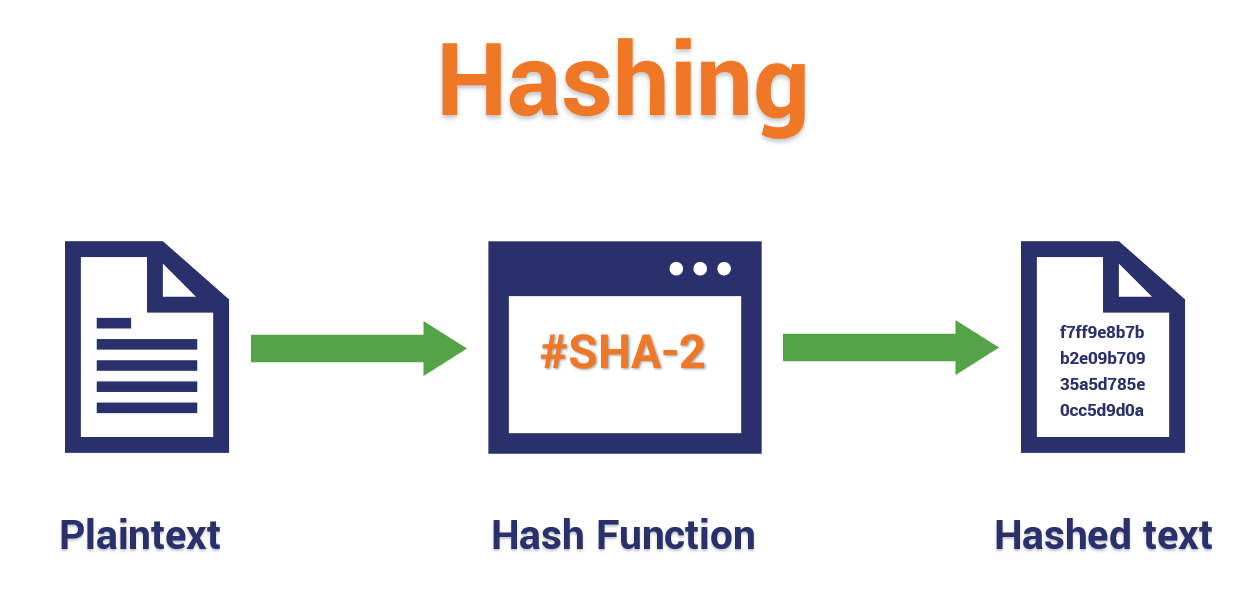
A simple illustration of what a hash function does by taking a plaintext data input and using a mathematical algorithm to generate an unreadable output.
Properties of Hash Function:
The ideal cryptographic hash function has the following main properties:
- Deterministic: This means that the same message always results in the same hash.
- Quick: It is quick to compute the hash value for any given message.
- Avalanche Effect: This means that every minor change in the message results in a major change in the hash value.
- One-Way Function: You cannot reverse the cryptographic hash function to get to the data.
- Collision Resistance: It is infeasible to find two different messages that produce the same hash value.
- Pre-Image Resistance: The hash value shouldn’t be predictable from the given string and vice versa.
- Second Pre-Image Resistance: Given an input, it should be difficult to find another input that has the same hash value.
Purpose of Hash Function
One purpose of a hash function in cryptography is to take a plaintext input and generate a hashed value output of a specific size in a way that can’t be reversed. But they do more than that from a 10,000-foot perspective. You see, hash functions tend to wear a few hats in the world of cryptography. In a nutshell, strong hash functions:
- Ensure data integrity,
- Secure against unauthorized modifications,
- Protect stored passwords, and
- Operate at different speeds to suit different purposes.
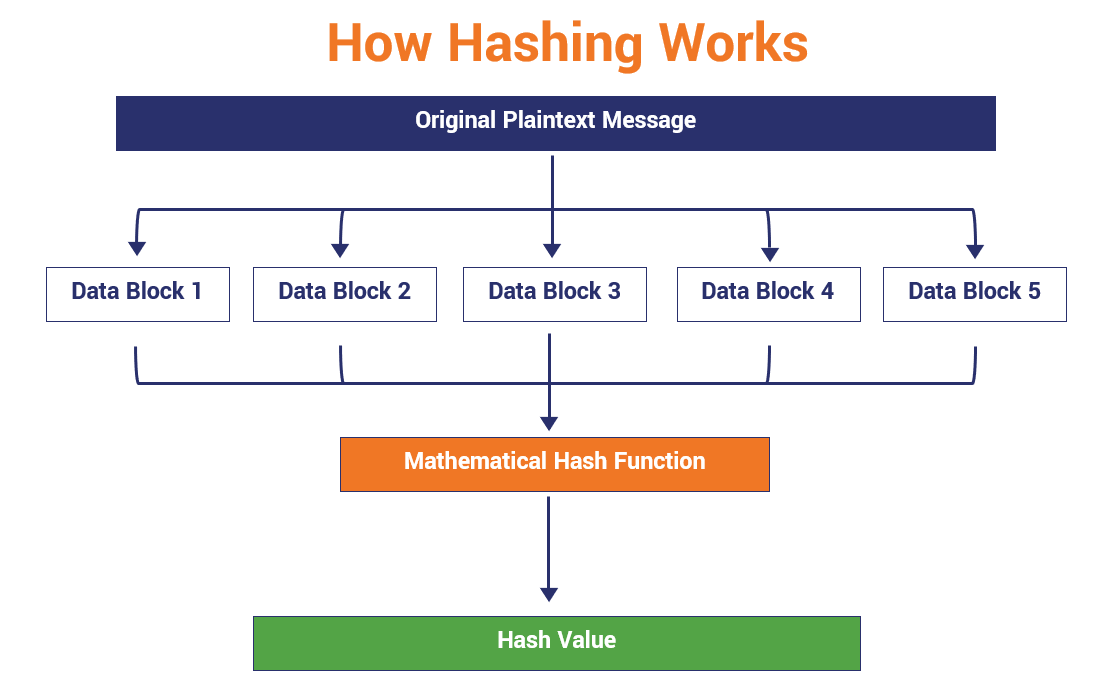
Working of Hash Function
When you hash a message, you take a string of data of any size as your input, run it through a mathematical algorithm that results in the generation of an output of a fixed length.
In some methods of hashing, that original data input is broken up into smaller blocks of equal size. If there isn’t enough data in any of the blocks for it to be the same size, then padding (1s and 0s) can be used to fill it out. Then those individual blocks of data are run through a hashing algorithm and result in an output of a hash value.