Basic Architecture of HBase
Need for HBase
Apache Hadoop has gained popularity in the big data space for storing, managing and processing big data as it can handle high volumes of multi-structured data. However, Hadoop cannot handle high velocity of random writes and reads and also cannot change a file without completely rewriting it. HBase is a NoSQL, column oriented database built on top of hadoop to overcome the drawbacks of HDFS as it allows fast random writes and reads in an optimized way. Also, with exponentially growing data, relational databases cannot handle the variety of data to render better performance. HBase provides scalability and partitioning for efficient storage and retrieval.
Hadoop Distributed File System (HDFS) and Apache HBase serve different purposes within the Hadoop ecosystem, and they are often used together to address different types of data storage and processing requirements.
Data Storage Model:
HDFS: It is a distributed file system designed for storing large files in a fault-tolerant manner. HDFS is optimized for batch processing and is well-suited for storing and processing large volumes of data in a write-once, read-many fashion. It provides high-throughput access to large data sets and is the primary storage system for Hadoop MapReduce jobs.
HBase: While HDFS is excellent for storing and processing large files, HBase is designed for random access to smaller pieces of data. It provides a NoSQL database model with key-value pairs and is suitable for scenarios where fast and random access to specific data points is essential, such as for real-time analytics or interactive querying.
HBase –Understanding the Basics
HBase is a data model similar to Google’s big table that is designed to provide random access to high volume of structured or unstructured data. HBase is an important component of the Hadoop ecosystem that leverages the fault tolerance feature of HDFS. HBase provides real-time read or write access to data in HDFS. HBase can be referred to as a data store instead of a database as it misses out on some important features of traditional RDBMs like typed columns, triggers, advanced query languages and secondary indexes.
HBase Data Model
HBase data model stores semi-structured data having different data types, varying column size and field size. The layout of HBase data model eases data partitioning and distribution across the cluster. HBase data model consists of several logical components- row key, column family, table name, timestamp, etc. Row Key is used to uniquely identify the rows in HBase tables. Column families in HBase are static whereas the columns, by themselves, are dynamic.
- HBase Tables – Logical collection of rows stored in individual partitions known as Regions.
- HBase Row – Instance of data in a table.
- RowKey -Every entry in an HBase table is identified and indexed by a RowKey.
- Columns - For every RowKey an unlimited number of attributes can be stored.
- Column Family – Data in rows is grouped together as column families and all columns are stored together in a low level storage file known as HFile.
HBase Storage Mechanism
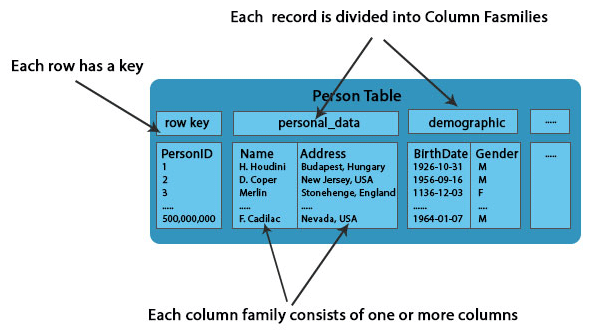
In HBase, Data is stored in the table, as shown above.Each row has a key.
- Column: It is a collection of data belonging to one column family, which is included inside the row.
- Column Family: Each column family consists of one or more columns.Each table contains a collection of Columns Families. These Columns are not part of the schema.HBase has Dynamic Columns. Different cells can have other columns because column names are encoded inside the cells.
- Column Qualifier: Column name is known as the Column qualifier.
Hbase Architecture:
HBase is a data model and is similar to Google's big table. It is an open-source, distributed database developed by Apache software foundation written in Java.
The table in HBase is split into regions and served by the region servers in HBase. Regions are vertically divided by column families into "stores." Stores are usually saved as files in HDFS. HBase runs on top of HDFS (Hadoop Distributed File System).
The following figure represents the architecture of HBase:
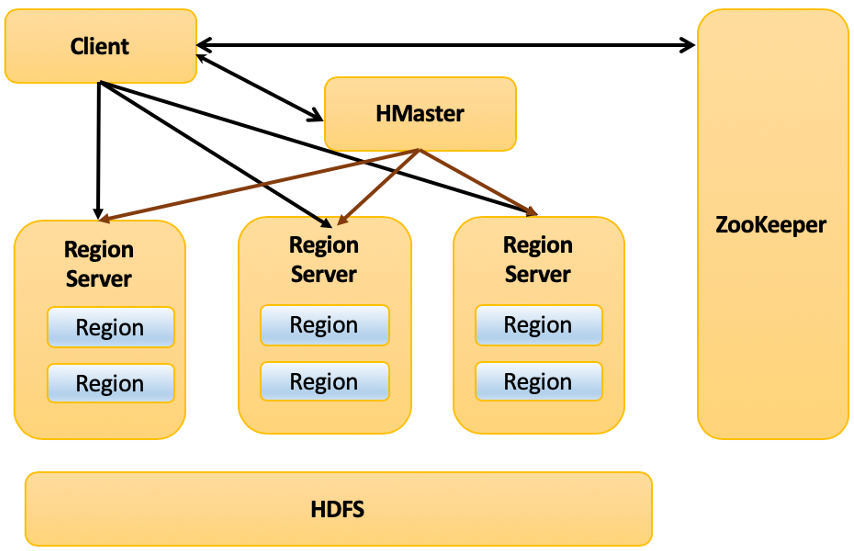
Components of Hbase
There are three major components of Hbase that are:
- Region Server
- HMaster
- Zookeeper
Region Server
Regions are the tables split up and spread across the region servers. The basic building blocks of the HBase cluster are regions that consist of the distribution of tables and are comprised of Column families. The size of a region is 256 MB by default.
The region servers have :
- Regions that communicate with the client and handle data-related operations.
- Regions that decide the region's size by following the region size thresholds.
- Regions that can handle read and write requests for all the sub-regions under it.
When the client reads and writes requests received by the HBase Region Server, it assigns the request to a region specifically, where the actual column family resides. The client can contact HRegion servers directly, and there is no need for mandatory permission of the HMaster to the client regarding communication with HRegion servers. Whenever the operations related to metadata and schema changes are required, the client requires HMaster help.
HMaster
HMaster acts as a monitoring agent that monitors all Region Server instances present in the cluster, and it acts as an interface for all the metadata changes.
HMaster performs the following major roles in HBase:
- HMaster provides admin performance and helps to distribute services to different region servers.
- It also plays a vital role in the performance and maintenance of nodes in the cluster.
- HMaster assigns regions to region servers.
- When a client needs to change any schema and any Metadata operations, HMaster takes responsibility for these operations.
Note:
The client communicates with both HMaster and ZooKeeper in a bi-directional way. It directly contacts HRegion servers for read and write operations. HMaster assigns regions to various region servers and, in turn, checks the health status of region servers.
Zookeeper
Zookeeper is an open-source project. HMaster and HRegionServers register themselves with ZooKeeper.
It provides various services like maintaining configuration information, naming, providing distributed synchronization, etc. Distributed Synchronization is the process of providing coordination services between nodes to access running applications. It has ephemeral nodes that represent region servers. Master servers use these nodes to search for available servers.
These nodes are also used to track network partitions and server failures. Zookeeper is the interacting medium between the Client region server. If a client wants to communicate with the region server, the zookeeper is the communication medium.
Apache ZooKeeper is a distributed coordination service that plays a crucial role in many distributed systems, including Apache HBase. In the context of HBase, ZooKeeper serves several important purposes:
- Distributed Configuration Management:HBase uses ZooKeeper to manage and distribute configuration information across the nodes in the HBase cluster. This includes information such as the location of HBase regions, the current state of the cluster, and various runtime parameters. ZooKeeper ensures that all nodes in the HBase cluster have consistent and up-to-date configuration information.
- Leader Election:HBase employs a distributed architecture with a master server (HMaster) that manages metadata and coordinates tasks such as region assignment. ZooKeeper is used to perform leader election for the HMaster role. In the event of a failure or during the startup of an HBase cluster, ZooKeeper helps in determining which node should take on the role of the HMaster.
- Cluster Coordination:ZooKeeper helps in maintaining coordination among the various components of an HBase cluster. For example, it is used to coordinate the assignment of regions to region servers, ensuring that each region is served by a specific region server.
- Locking and Synchronization:HBase uses ZooKeeper for distributed locking mechanisms, which are essential for coordinating access to critical resources across multiple nodes. For instance, ZooKeeper can be used to implement locks that prevent multiple processes or nodes from modifying certain pieces of data simultaneously.
- Notifications and Event Handling:ZooKeeper provides a notification mechanism that allows HBase nodes to be notified of changes in the cluster state. This is particularly useful for maintaining an up-to-date view of the cluster and responding to changes dynamically.
- Failure Detection:ZooKeeper helps in detecting failures within the HBase cluster. Nodes can register themselves with ZooKeeper, and if a node fails or becomes unreachable, ZooKeeper can notify the other nodes about the change in the cluster's state.
- Sequential Node IDs:In certain scenarios, ZooKeeper can be used to generate sequential node IDs. This is useful in ensuring a globally unique order for operations in a distributed system.
Basic Architecture of Cassandra
Cassandra is a distributed NoSQL database that uses a column-family data model. It is designed to handle large amounts of data with high availability and scalability. Cassandra provides a fault-tolerant architecture that is designed to handle failure gracefully and continue to provide uninterrupted service.
Cassandra was created to address the limitations of traditional relational databases, such as MySQL and Oracle, which were not designed to handle the massive amounts of data generated by modern web applications. At Facebook, traditional databases were proving to be a bottleneck for their infrastructure and unable to keep up with the scale of data that needed to be processed.
To address these limitations, Facebook engineers Avinash Lakshman and Prashant Malik began working on a distributed database that could scale horizontally by adding more nodes and handle large amounts of data with low latency. They drew inspiration from the Amazon Dynamo paper and created a new distributed database that could handle the massive amounts of data generated by Facebook's users.
After its successful deployment at Facebook, Cassandra was released as an open-source project in 2009 under the Apache Software Foundation. Since then, it has gained popularity and is used by several large companies, including Apple, Netflix, and Twitter.
Cassandra is based on the idea of a ring of nodes, where each node in the ring is responsible for storing a portion of the data. This allows for horizontal scaling, where more nodes can be added to the cluster to handle additional data. Cassandra also provides automatic replication of data across multiple nodes, ensuring high availability and fault tolerance.
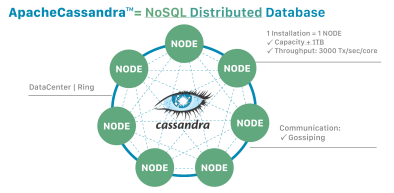
Image source: cassandra
Cassandra's data model is based on the concept of a column family, which is similar to a table in a traditional relational database. However, unlike traditional databases, Cassandra allows for dynamic addition and removal of columns without the need for a schema update. This allows for flexibility in data modeling and makes it easy to handle data that may change frequently.
Architecture
Cassandra is a distributed NoSQL database that uses a peer-to-peer architecture. Data is partitioned across multiple nodes, and each node in the cluster is responsible for storing and processing a portion of the data. This allows for horizontal scaling, where additional nodes can be added to the cluster to handle additional data.
Cassandra's architecture is based on the Amazon Dynamo paper and uses a decentralized, peer-to-peer model. Cassandra uses a ring-based architecture, where each node in the cluster is assigned a token that determines its position in the ring. The ring allows for horizontal scaling, where additional nodes can be added to the cluster to handle additional data.
Cassandra uses a distributed hash table (DHT) to partition data across multiple nodes in the cluster. Data is partitioned using a consistent hashing algorithm, which ensures that each node in the cluster is responsible for an equal portion of the data. Each node is also responsible for replicating its portion of the data to other nodes in the cluster for fault tolerance and high availability.
6
Cassandra's data model is based on the concept of a column family. A column family is similar to a table in a traditional relational database but allows for dynamic addition and removal of columns without the need for a schema update. This provides flexibility in data modeling and makes it easy to handle data that may change frequently.
Each token in a node represents a portion of the data, and the nodes responsible for that portion of the data are determined by the token values. Data is replicated across multiple nodes for fault tolerance and high availability.
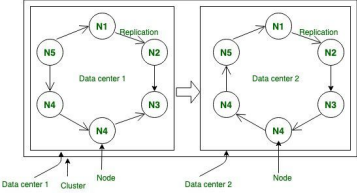
Image: source
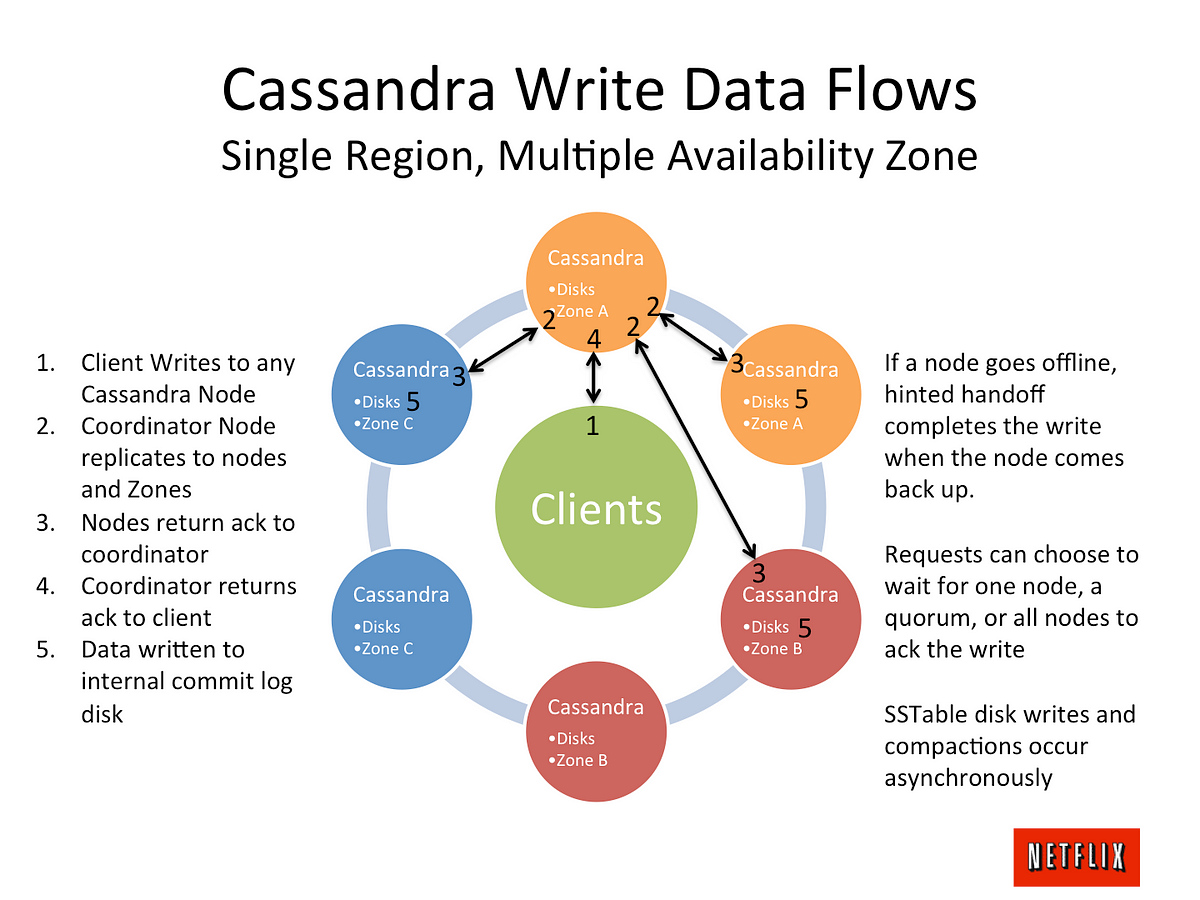
When a client wants to read or write data, it sends a request to one of the nodes in the cluster. The node receiving the request acts as the coordinator and is responsible for coordinating the request with the other nodes in the cluster. The coordinator determines which nodes in the cluster are responsible for the requested data and forwards the request to those nodes. The data is then returned to the coordinator, which sends it back to the client.
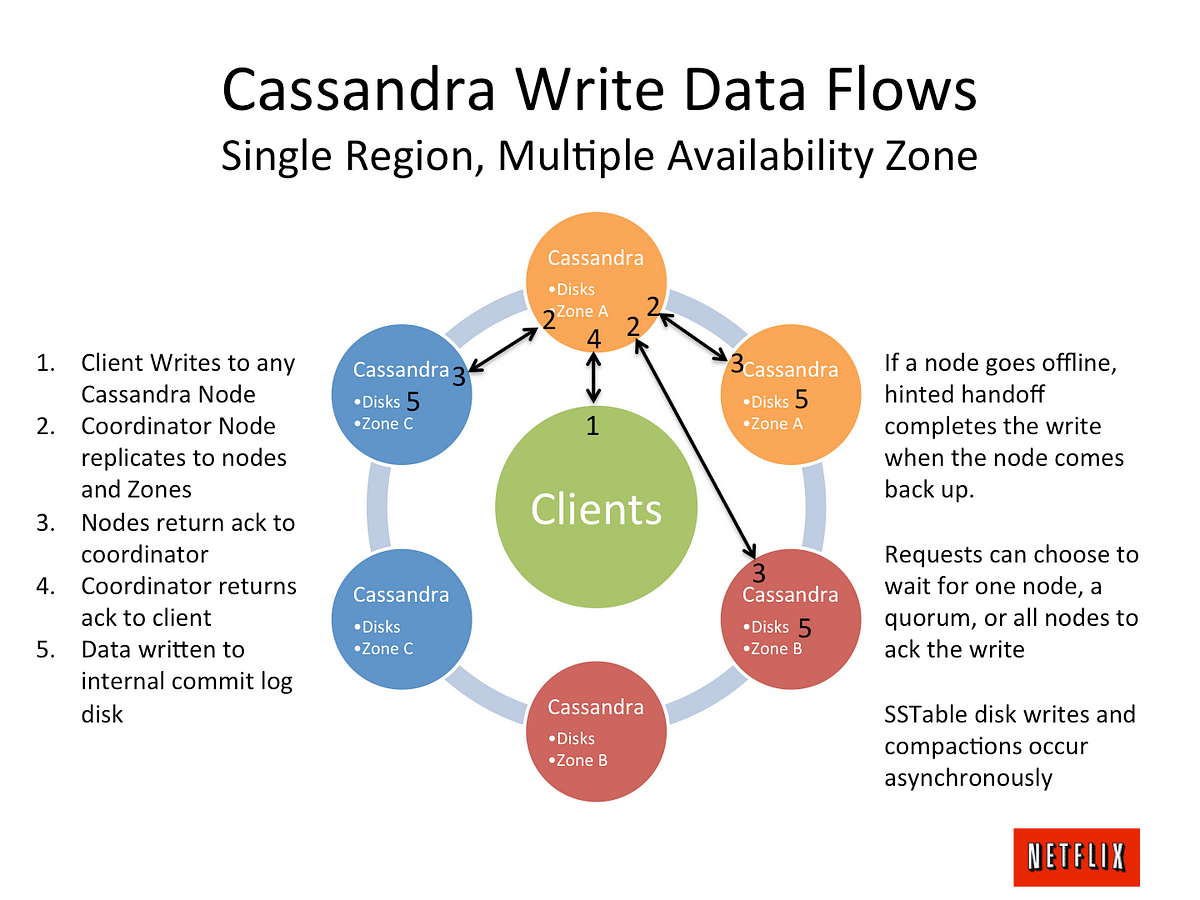
Image: Link
Components of Cassandra:
Node: A node is a single instance of Cassandra running on a server. Each node in the cluster is assigned a token that determines its position in the ring and is responsible for storing and processing a portion of the data.
Cluster: A cluster is a group of nodes that work together to provide a distributed database. Cassandra clusters can consist of hundreds or thousands of nodes.
Datacenter: A datacenter is a group of nodes that are geographically close to each other and communicate with each other using high-speed local networks. Datacenters allow for the distribution of data across multiple geographic locations for fault tolerance and disaster recovery.
Commit Log: The commit log is a durable, sequential write-ahead log that records all changes to the database. The commit log ensures that changes are not lost in the event of a node failure.
Memtable: The memtable is an in-memory data structure that stores recently updated data. The memtable is periodically flushed to disk to create an SSTable.
SSTable: The SSTable is an immutable, on-disk data structure that stores data sorted by key. SSTables are merged periodically to optimize read performance.
8
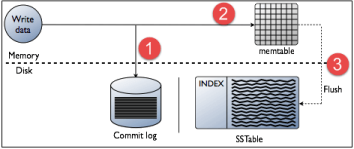
Write: When a client writes data to Cassandra, the data is first written to the commit log and then stored in the memtable. The data is also replicated to other nodes in the cluster for fault tolerance.
Read: When a client reads data from Cassandra, it sends a read request to one of the nodes in the cluster. The node acts as the coordinator and forwards the request to the nodes responsible for the requested data. The data is then returned to the coordinator and
Basic Architecture of MongoDB
Background
MongoDB is a popular document-oriented NoSQL database that was first released in 2009 by the software company MongoDB Inc. It was created by Dwight Merriman and Eliot Horowitz, who were developers at DoubleClick, a company that was later acquired by Google.
Before MongoDB, the predominant database technologies were relational databases, such as MySQL and PostgreSQL. However, these databases were not designed to handle the variety and complexity of data that was becoming more common with the rise of big data and web-scale applications. As a result, developers needed a database that was more flexible, scalable, and easy to use.
MongoDB was designed to address these needs by providing a document-based data model, horizontal scaling capabilities, and easy integration with programming languages. MongoDB uses a flexible data model that allows developers to store data in a format that closely mirrors the application's data model. This document-based data model allows for more natural and efficient data retrieval and manipulation.
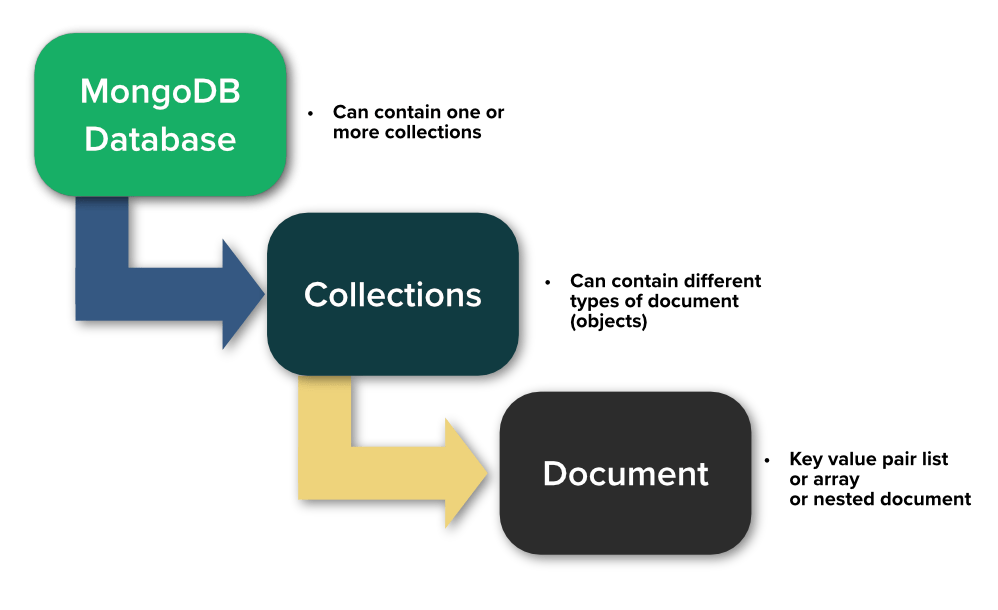
Image: Link
Furthermore, MongoDB was designed to scale horizontally by allowing for the distribution of data across multiple nodes in a cluster. This approach enables developers to scale their applications to handle larger datasets and higher traffic volumes. MongoDB also supports sharding, which allows for data to be partitioned across multiple servers, increasing the performance and reliability of the database.
Since its initial release, MongoDB has gained widespread adoption among developers and companies, including eBay, Cisco, and Adobe. In 2013, MongoDB Inc. became a publicly traded company on the NASDAQ stock exchange, and it continues to be one of the most popular NoSQL databases in use today.
10

Architecture
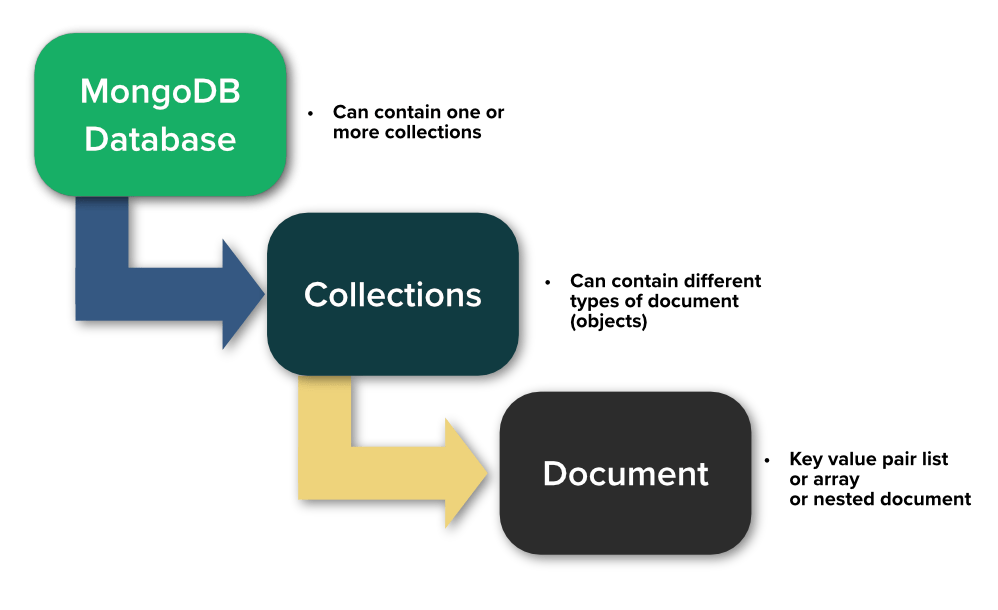
MongoDB is a document-oriented NoSQL database that uses a flexible data model to store data. In MongoDB, data is stored as documents in BSON format (a binary representation of JSON). Each document can have a different structure, and fields within a document can vary in type and size.
When a client wants to read or write data, it sends a request to the MongoDB server. The server processes the request and returns the data to the client. MongoDB supports a range of queries, including ad-hoc queries, aggregation queries, and full-text search.
MongoDB uses a distributed architecture, where data is distributed across multiple nodes in a cluster. The cluster consists of one or more shards, which are collections of nodes that store a portion of the data. Each shard is composed of one or more replica sets, which are groups of nodes that store identical copies of the data for fault tolerance and high availability.
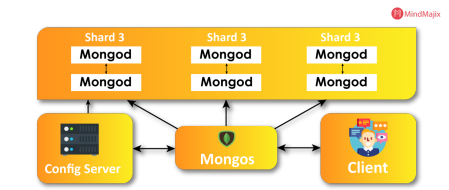
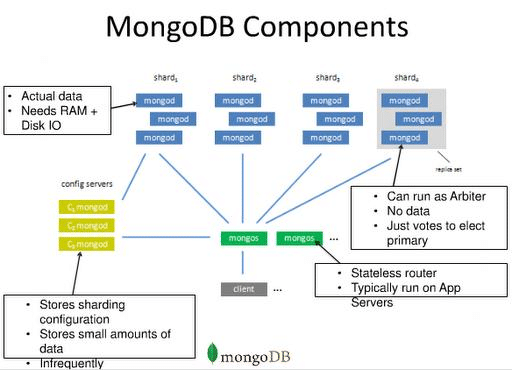
The MongoDB architecture includes:
In MongoDB, there are several key components that work together to provide a scalable and reliable database system. These components include mongos, mongod, shards, and config servers.
mongos: Mongos is a query router that sits between client applications and the MongoDB cluster. When a client sends a query to the database, the mongos component routes the query to the appropriate shard or shards, based on the query's target data range. Mongos also provides a unified view of the entire cluster, hiding the underlying complexity of the distributed database from the client.
mongod: Mongod is the primary database server in MongoDB. It manages the database files, indexes, and other data structures on disk. Mongod can operate as a standalone server, or as part of a replica set, which is a group of mongod servers that replicate data to provide high availability and fault tolerance.
Shards: Shards are individual database servers that store a subset of the data in the MongoDB cluster. A shard can consist of one or more mongod instances, which collectively store a portion of the database. Sharding allows MongoDB to distribute data across multiple servers, providing horizontal scalability and high performance for large-scale applications.
Config servers: Config servers store the metadata and configuration information about the MongoDB cluster. They maintain a record of the location of each shard and the ranges of data stored on each shard. Config servers provide a centralized repository of metadata for the cluster, allowing the mongos query router to determine where data is located and how to route queries to the appropriate shard.
Node: A node is a single instance of MongoDB running on a server. Each node can store a portion of the data and can be part of a replica set or shard.
Replica set: A replica set is a group of nodes that store identical copies of the data. Each replica set includes one primary node that handles all write operations and multiple secondary nodes that replicate the data from the primary node.
{kind=link}
{kind=link}
{kind=link}
Image: Link
{kind=link}
Operations in MongoDB:
Write: When a client writes data to MongoDB, the data is first written to the primary node in the replica set. The primary node then replicates the data to the secondary nodes for fault tolerance and high availability.
Read: When a client reads data from MongoDB, it sends a read request to the query router. The query router determines which nodes in the cluster are responsible for the requested data and forwards the request to those nodes. The data is then returned to the query router, which sends it back to the client.
Aggregation: MongoDB supports aggregation queries, which allow developers to perform complex data analysis and aggregation on large datasets. Aggregation queries can be used to group, filter, and transform data in a variety of ways.
Full-text search: MongoDB supports full-text search, which allows developers to perform keyword searches on text data stored in the database. Full-text search in MongoDB uses text indexes, which are created on fields that contain text data.
Other references:
References:
https://www.kdnuggets.com/2021/02/understanding-nosql-database-types-column-oriented-databases.html
https://www.mongodb.com/document-databases
https://neo4j.com/developer/graph-database/