- Introduction To Sql
- Features Of Sql
- Queries And Sub Queries
- Set Operations
- Relations (Joined And Derived)
- Queries Under Ddl And Dml Commands
- Embedded Sql
- Views
- Relational Algebra
- Database Modification
- Qbe And Domain Relational Calculus
- Sql Queries Practice Questions
- Relational Algebra Practice Question
LOG BASED RECOVERY
Log-based recovery is a critical mechanism in a Database Management System (DBMS) to ensure data integrity and consistency in the event of failures.
To ensure atomicity, modifications made by an aborted transaction should not be visible in the database, while those made by a committed transaction should be. To achieve this, the user must first write stable storage information detailing the modifications, without directly altering the database.
This information will help ensure that all changes made by committed transactions are accurately reflected in the database.
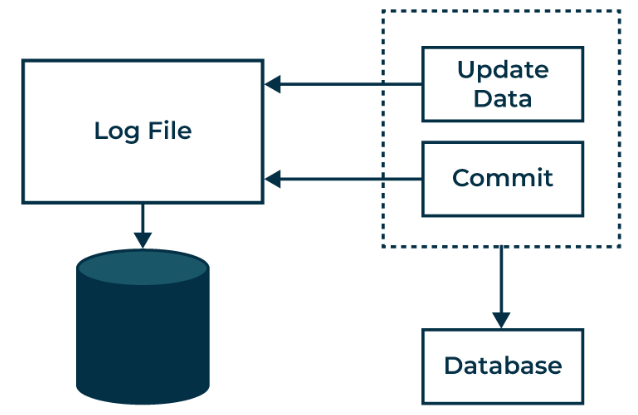
- Transaction Log:
Every operation performed on the database is recorded in the log. Before making any modifications to the database, an updated log record is created to document the change. An update log record, represented as <Ti, Xj, V1, V2>, includes the following fields:
- Transaction identifier: A unique identifier for the transaction that performed the write operation.
- Data item: A unique identifier for the data item being written.
- Old value: The value of the data item before the write operation.
- New value: The value of the data item after the write operation.
Two main types of logs:
- Redo Log (Forward Log): Contains information needed to redo changes made by a transaction.
- Undo Log (Backward Log): Contains information needed to undo changes made by a transaction.
- Write-Ahead Logging (WAL):
This rule ensures that all modifications are logged before they are applied to the database. Specifically, it requires that:
- Before a transaction’s changes are written to the database, the corresponding log records must be written to the log.
- Before a transaction is considered committed, its log records must be written to a stable storage.
- Checkpointing:
Periodic snapshots of the database state, which help reduce the amount of log data that must be processed during recovery. During recovery, the system only needs to consider transactions that were active at the time of the last checkpoint.
Types of Log-Based Recovery
- Deferred Update (No-Undo/Redo) Protocol:
In this method, updates are not applied to the database until the transaction reaches its commit point.
The log must contain a record of all changes so that, in the event of a failure, the changes can be redone from the log.
- Immediate Update (Undo/Redo) Protocol:
Updates are applied to the database as soon as they are made, but the changes are also logged so they can be undone if necessary.
Both redo and undo information is maintained in the log. This approach allows for more immediate reflection of changes but requires more sophisticated logging and recovery mechanisms.
Recovery Procedure
- Analysis Phase:
Determine the state of the transactions at the time of failure. Identify which transactions were committed, which were in progress, and which were aborted.
- Redo Phase:
Replay the logged operations for all committed transactions to ensure that all their changes are reflected in the database.
The redo operation starts from the last checkpoint and applies all the redo log entries to the database.
- Undo Phase:
Reverse the changes of all transactions that were active at the time of the failure but did not commit.
The undo operation involves reading the undo log entries and restoring the database to the state before those transactions began.
Example
Consider a transaction T1 that modifies a data item X from value 10 to 20. The log entries might look like this:
- start_transaction T1
- write_item T1, X, old_value: 10, new_value: 20
- commit T1
In the event of a failure, the recovery process would:
- Analyze the log to identify that T1 was committed.
- Redo the change to ensure that X = 20 is applied to the database, since T1 committed.
- No undo is necessary for committed transactions, but if there were any uncommitted transactions at the time of failure, their changes would be undone.
Advantages of Log-Based Recovery
- Data Integrity: Ensures that the database can be restored to a consistent state even after failures.
- Efficiency: Reduces the amount of work needed for recovery by focusing on changes since the last checkpoint.
- Concurrency: Allows for multiple transactions to be processed concurrently while maintaining data consistency.