- 1.1 Introduction To Distributed Systems
- 1.2 Examples Of Distributed Systems
- 1.3 Main Characteristics
- 1.4 Advantages And Disadvantages Of Distributed System
- 1.5 Design Goals
- 1.6 Main Problems
- 1.7 Models Of Distributed System
- 1.8 Resource Sharing And The Web Challenges
- 1.9 Types Of Distributed System: Grid, Cluster, Cloud
- Chapter 1 - Slides
- Case Study: Www As Distributed System
- 2.1 Introduction
- 2.2 Communication Between Distributed Objects
- 2.3 Remote Procedure Call
- 2.4 Events And Notifications
- 2.5 Java Rmi Case Study
- 2.6 Introduction To Dfs
- 2.7 File Service Architecture
- 2.8 Sun Network File System
- 2.9 Introduction To Name Services
- 2.10 Name Services And Dns
- 2.11 Directory And Discovery Services
- 2.12 Comparison Of Different Distributed File Systems
- Chapter 2- Slides
- 8.1 Transactions
- 8.2 Nested Transaction
- 8.3 Locks
- 8.4 Optimistic Concurrency Control
- 8.5 Timestamp Ordering
- 8.6 Comparison Of Methods For Concurrency Control
- 8.7 Introduction To Distributed Transactions
- 8.8 Flat And Nested Distributed Transactions
- 8.9 Atomic Commit Protocols
- 8.10 Concurrency Control In Distributed Transactions
- 8.11 Distributed Deadlocks
- 8.12 Transaction Recovery
- 2079 Bhadra-Regular
- 2076 Chaitra, Ashwin- Ioe Old Question Solution, Distributed System
- 2078 Bhadra- Ioe Old Question Solution, Distributed System
- 2069-Chaitra- Ioe Old Question Solution, Distributed System
- 2075- Regular And Back- Ioe Old Question Solution, Distributed System
- 2070-Back- Ioe Old Question Solution, Distributed System
- 2074 Regular/ Back- Ioe Old Question Solution, Distributed System
- 2072 Chaitra / Kartik- Ioe Old Question Solution, Distributed System
- 2079 Bhadra/ 2080 Baishakh- Ioe Old Question Solution, Distributed System
- 2071- Shrawan- Ioe Old Question Solution, Distributed System
- 2071 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Chaitra- Ioe Old Question Solution, Distributed System
- 2070 Ashadh-Ioe Old Question Solution, Distributed System
REPLICATION
In distributed systems, replication refers to the practice of maintaining multiple copies of data or services across different nodes (computers) in a network. This redundancy serves several purposes related to reliability, availability, and performance.
Reasons for Replication
Fault Tolerance and Reliability: By replicating data across multiple nodes, the system becomes more resilient to failures. If one node fails, other nodes can still provide the required data or service, ensuring continuous operation.
Improved Availability: Replication can improve the availability of data or services by placing copies closer to users or clients. This reduces latency and improves response times since data can be served from the nearest or least loaded replica.
Load Balancing: Distributing requests across multiple replicas helps balance the load on the system. Requests can be directed to the replica that is least busy or geographically closest to the requester, improving overall performance.
Scaling: Replication supports horizontal scaling by allowing additional replicas to be added as the system grows. This can be more cost-effective than vertically scaling a single node.
Caching: Replicas can also be used as caches to store frequently accessed data, reducing the need to fetch data from the primary storage or source.
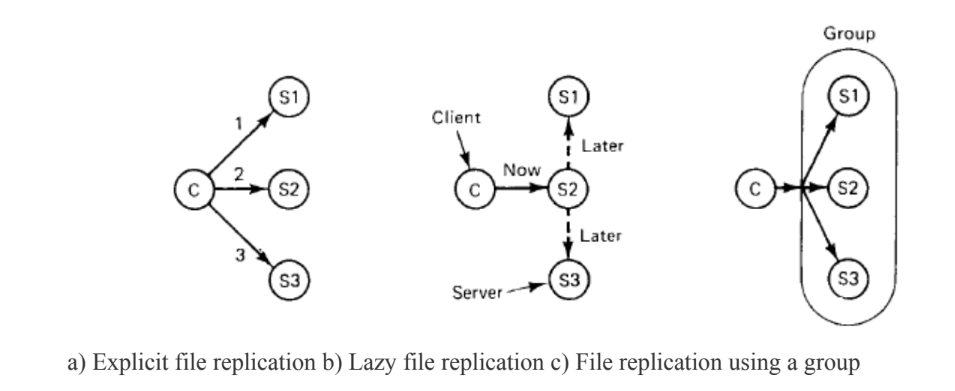
Types of Replication
Explicit Replication:
- Explicit replication involves explicitly specifying which data or operations should be replicated across multiple nodes or replicas within the system.
- Examples:
- Replicating critical configuration data across nodes in a cloud environment.
- Replicating frequently accessed files or databases across different data centers.
Lazy Replication:
- Lazy replication, also known as asynchronous replication, involves delaying the propagation of updates to replicas after they have been applied to the primary copy.
- Examples:
- Database systems using asynchronous replication to improve write performance and tolerate network latency.
- File synchronization tools that update replicas only when the primary copy changes, optimizing bandwidth usage.
Group Communication:
- Group communication replication involves coordinating and synchronizing updates across a group or cluster of nodes using a communication protocol.
- Examples:
- Distributed messaging systems using group communication protocols (e.g., Paxos, Raft) to achieve consensus and ensure that all nodes receive and process messages in a coordinated manner.
- Distributed databases employing group replication for maintaining data consistency and fault tolerance across multiple database nodes.