6.7 The Huffman algorithm
The Huffman algorithm is a technique used for constructing an optimal prefix-free binary tree called a Huffman tree or Huffman code, which is used for data compression. It was developed by David A. Huffman in 1952 while he was a Ph.D. student at MIT.
Definition:
The Huffman algorithm takes a set of symbols (such as characters in a text document) and their frequencies of occurrence as input and constructs a binary tree where the more frequently occurring symbols have shorter binary representations. This is achieved by assigning shorter codewords (binary representations) to the more frequent symbols and longer codewords to the less frequent symbols. The resulting binary tree, known as a Huffman tree, can then be used to encode and decode data efficiently.
Significance of Huffman Algorithm:
Data Compression: The primary significance of the Huffman algorithm is its use in data compression. By assigning shorter codewords to frequently occurring symbols and longer codewords to infrequently occurring symbols, the Huffman algorithm enables efficient data compression, reducing the amount of storage space required to represent the data.
Lossless Compression: Huffman coding is a form of lossless data compression, meaning that the original data can be perfectly reconstructed from the compressed data. This makes it suitable for applications where preserving the integrity of the data is essential, such as text and image compression.
Optimality: The Huffman algorithm produces an optimal prefix-free binary tree for a given set of input symbols and their frequencies. This means that no other prefix-free binary tree can achieve better compression ratios for the same set of symbols and frequencies.
Widely Used: Huffman coding is widely used in various applications, including file compression algorithms like ZIP and gzip, communication protocols, image and video compression standards (such as JPEG and MPEG), and many other areas where efficient data representation and transmission are critical.
Huffman Coding Algorithm Example
Construct a Huffman tree by using these nodes.
|
Value |
A |
B |
C |
D |
E |
F |
|
Frequency |
5 |
25 |
7 |
15 |
4 |
12 |
Step 1: According to the Huffman coding we arrange all the elements (values) in ascending order of the frequencies.
|
Value |
E |
A |
C |
F |
D |
B |
|
Frequency |
4 |
5 |
7 |
12 |
15 |
25 |
Step 2: Insert first two elements which have smaller frequency.
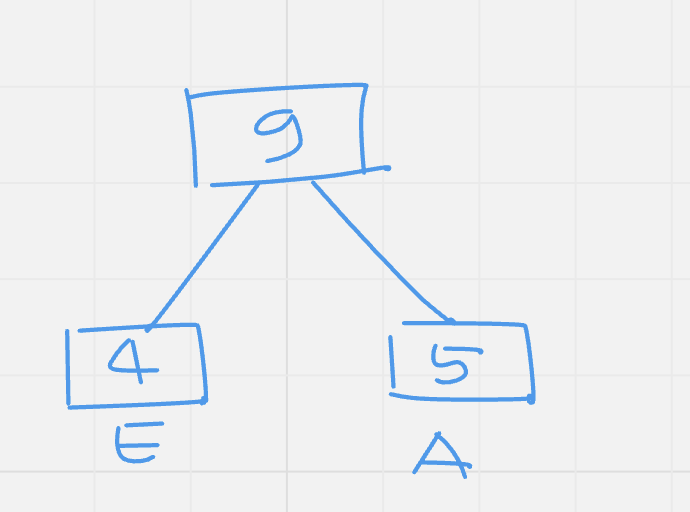
|
Value |
C |
EA |
F |
D |
B |
|
Frequency |
7 |
9 |
12 |
15 |
25 |
Step 3: Take the next smaller number and insert it at the correct place.
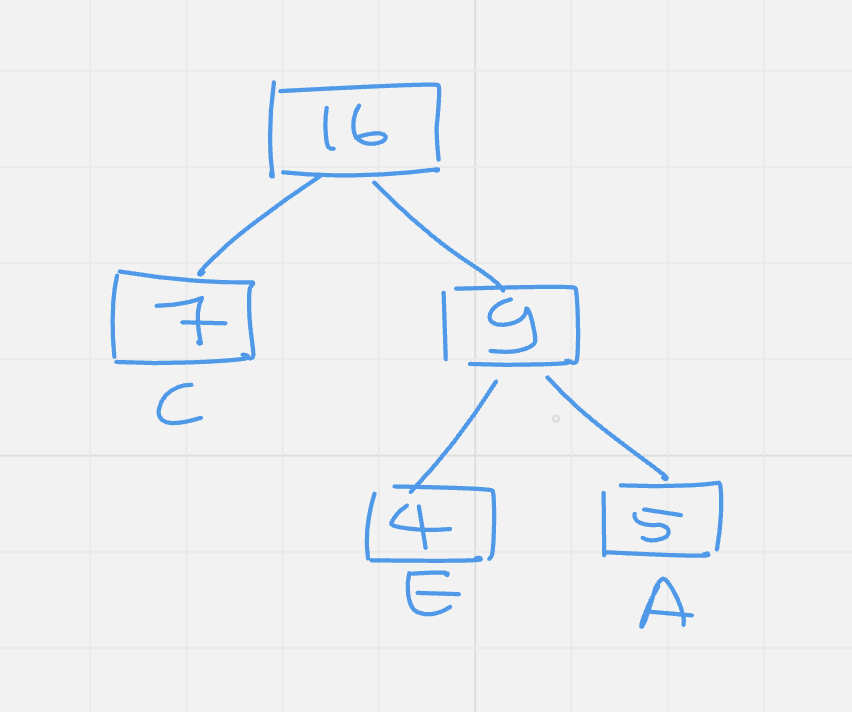
|
Value |
F |
D |
CEA |
B |
|
Frequency |
12 |
15 |
16 |
25 |
Step 4: Next elements are F and D so we construct another subtree for F and D.
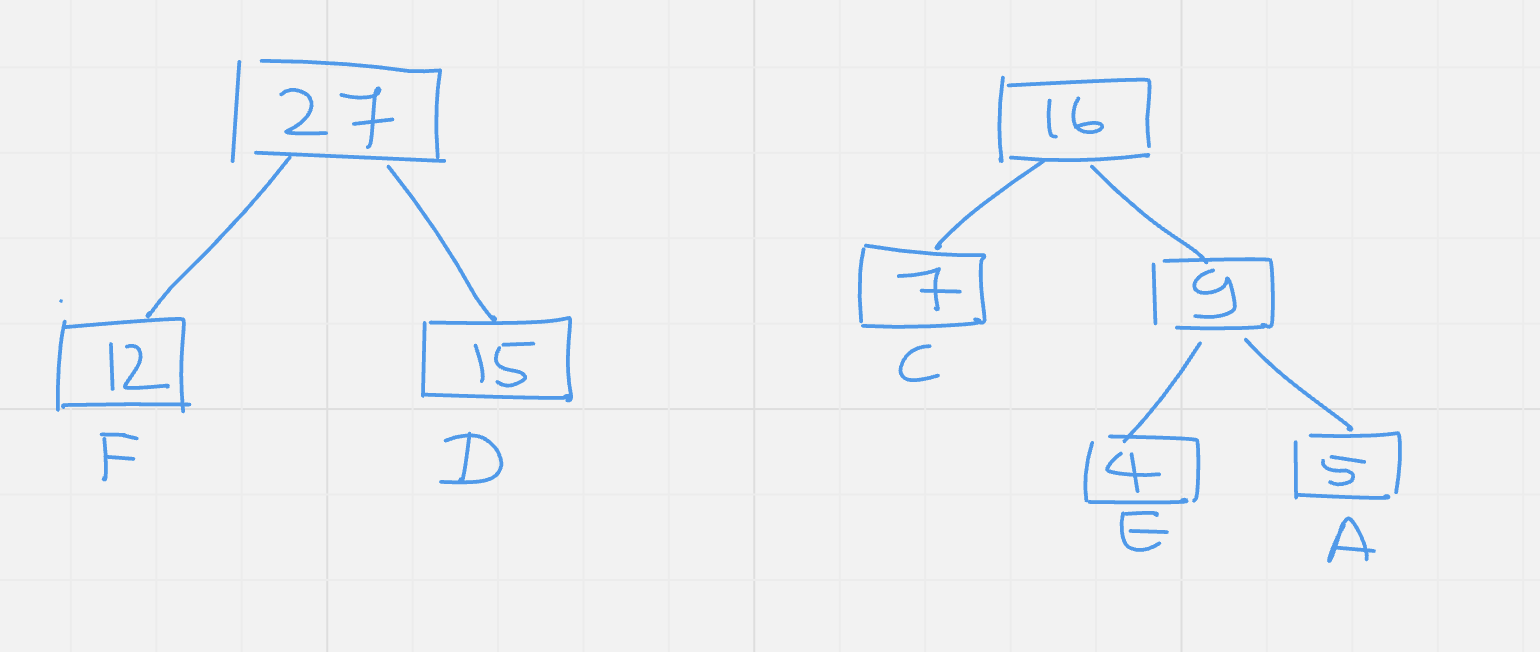
|
Value |
CEA |
B |
FD |
|
Frequency |
16 |
25 |
27 |
Step 5: Take the next value having smaller frequency then add it with CEA and insert it at the correct place.
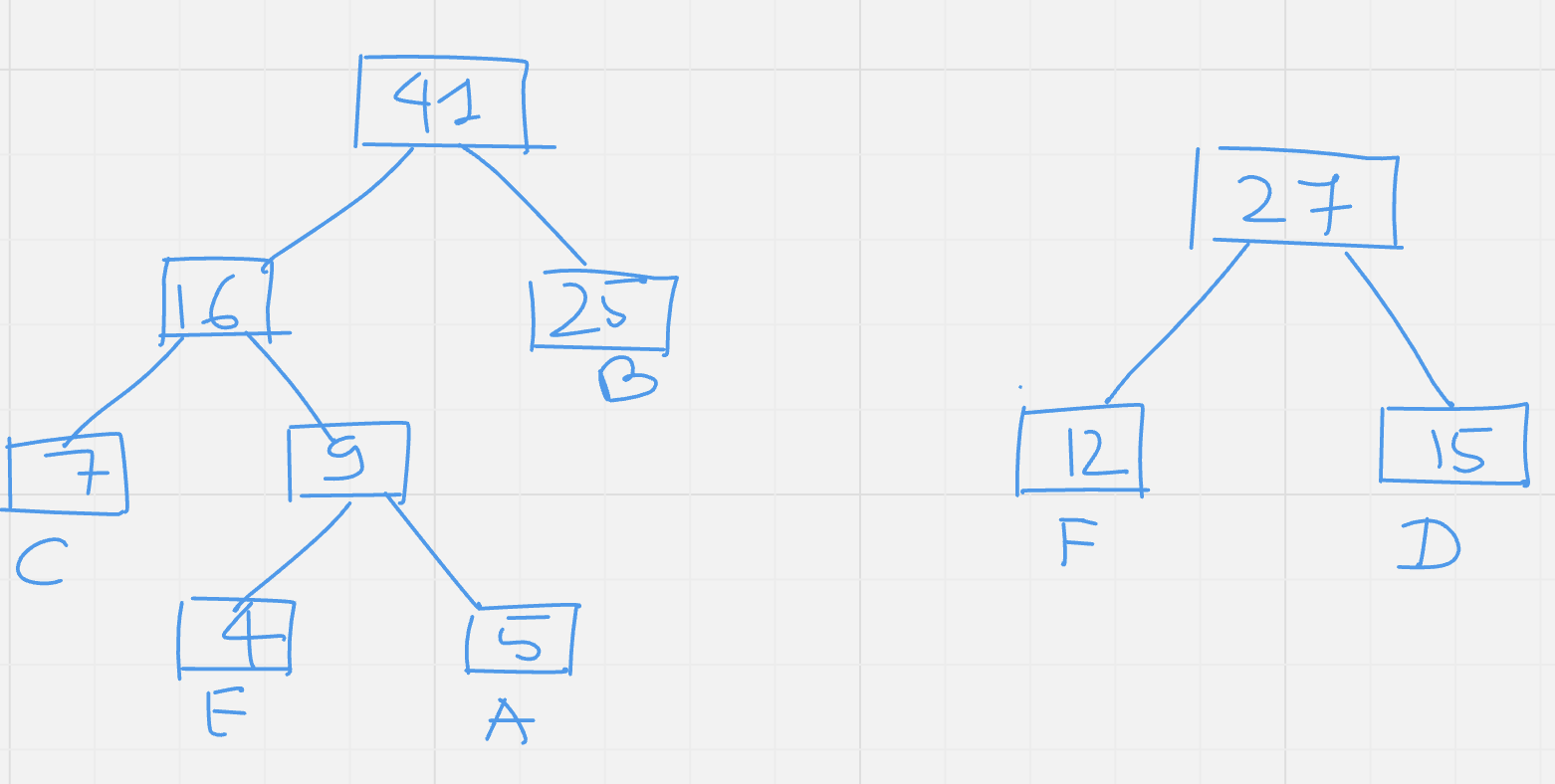
|
Value |
FD |
CEAB |
|
Frequency |
27 |
41 |
Step 6: We have only two values hence we can combine them by adding them.
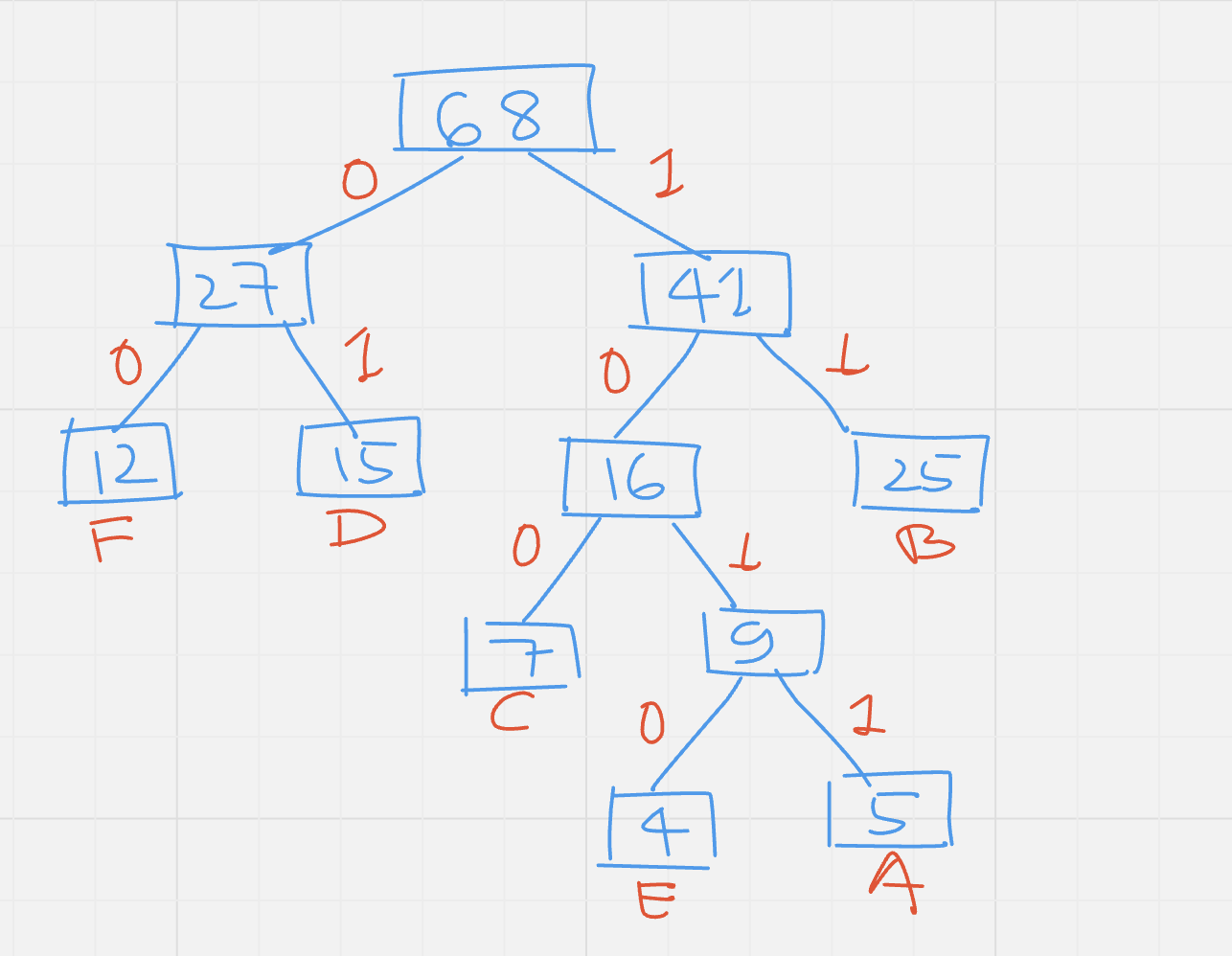
From the above binary tree, get the codes for each character as follows:
A 1011
B 11
C 100
D 01
E 1010
F 00
For decoding the code we can take the code and traverse it through the tree, for example: for code: 1010 , start with the right subtree and follow the code to the leaf node, labeled as E.
Find out the Huffman code for the given string: ABRACADABRA
Step 1: Calculate the frequency of each character in the string
|
A |
B |
R |
C |
D |
|
5 |
2 |
2 |
1 |
1 |
Step 2: Sort the characters in ascending order of the frequency. Store them in priority queue Q
|
C |
D |
B |
R |
A |
|
1 |
1 |
2 |
2 |
5 |
Step 3: Dequeue first two minimum values from Q, create a node, assign first minimum value as left child of the node and second minimum value as the right child of the node and assign sum of these minimum values as value of new node. Finally, enqueue the value of the new node into Q.
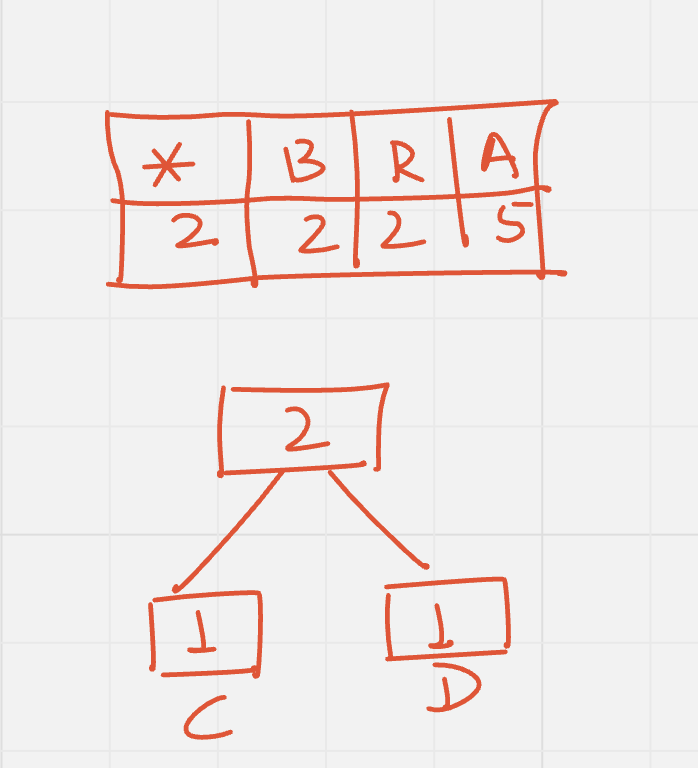
Repeat the above steps until the Q is empty. Finally Assign 0 to every left edge and 1 to every right edge of the tree.
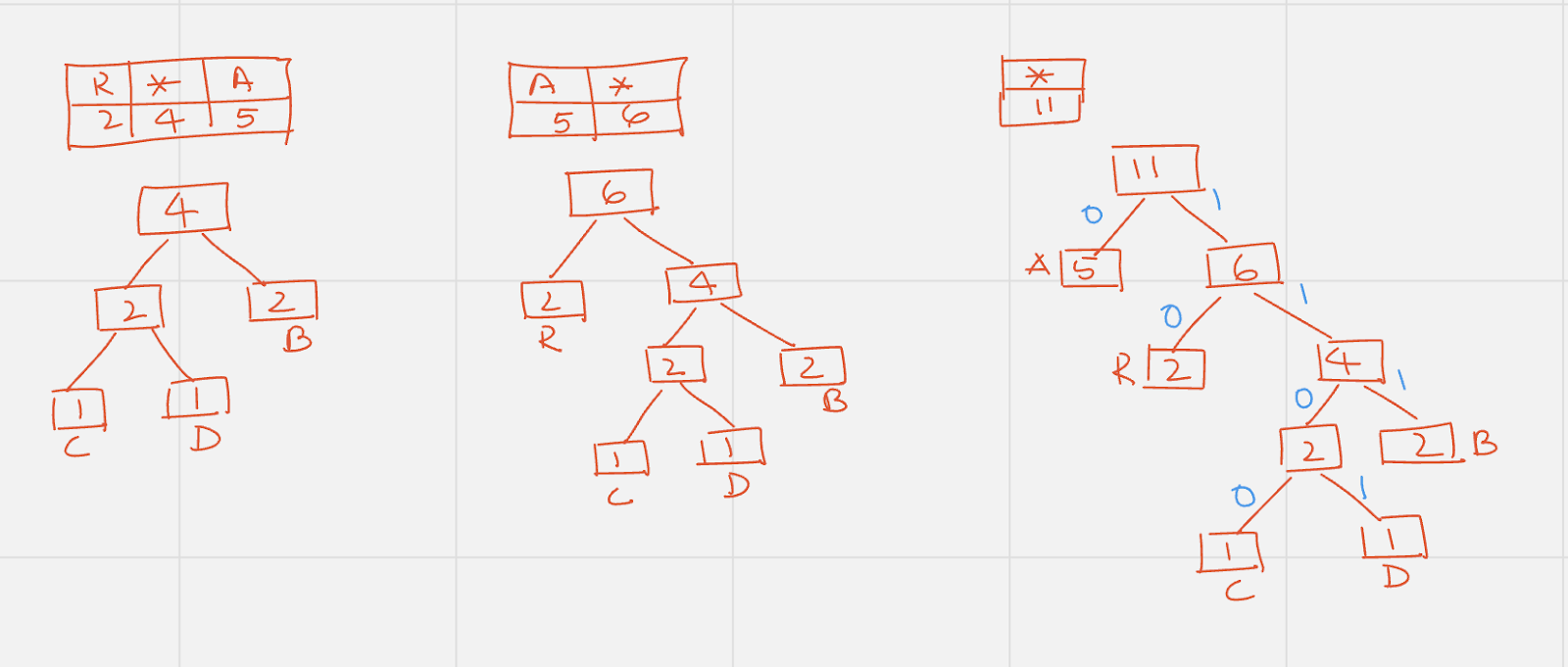
From the above binary tree, get the codes for each character as follows:
|
A |
0 |
5 X 1 = 5 |
|
B |
111 |
2 X 3 = 6 |
|
C |
1100 |
1 X 4 = 4 |
|
D |
1101 |
1 X 4 = 4 |
|
R |
10 |
2 X 2 = 4 |
From the above table it is clear that the most frequent character : A is represented by single bit 0. Hence total memory requirement to encode the string ABRACADABRA is: (5+6+4+4+4 = 23 bit). If we compare the huffman code with ASCII code the ASCII encoding will require: 11 X 8(as each character need 1 byte) = 88 bit.